




If you're running AI agents in production, somewhere between a fifth and two-thirds of your LLM API calls are generating responses that already exist. Not approximately exist. Semantically identical responses to semantically identical questions, phrased slightly differently every time.
You're paying full price for each one.
This isn't a theory. There's a growing body of research on semantic caching for LLM APIs, and the numbers are striking. But the research also has real limits that nobody seems to talk about. The studies measure caching in isolation, on narrow workloads, with static query distributions. They don't account for how cache hit rates change over time as the system learns, or how different agent workloads produce wildly different repetition patterns.
We've been thinking about this problem in the context of building infrastructure for AI agents. What follows is a breakdown of what the research actually says, where it falls short, and our own framework for estimating LLM call reduction across different enterprise workloads. The estimates at the end are ours. We'll show our reasoning so you can pick them apart.
What the Research Says
The core mechanism is simple. Instead of caching LLM responses by exact query text (which almost never matches because humans don't phrase things identically), you cache by semantic similarity. Convert the query to a vector embedding, compare it against previously cached query embeddings, and if the similarity exceeds a threshold, return the cached response without calling the LLM at all.
The question is: how often does this actually work?
A peer-reviewed study on GPT Semantic Cache found that for e-commerce customer queries (order status, shipping, product features), the system eliminated up to 68.8% of API calls with cache hit rates between 61.6% and 68.8%. Accuracy on those hits exceeded 97%. For predictable, pattern-heavy queries, semantic caching works well.
A VentureBeat case study reported a 67% cache hit rate in production, cutting LLM API costs by 73%. But there's an important detail buried in that article: analysis of 100,000 production queries found that only 18% were exact duplicates, while 47% were semantically similar. That 47% is the ceiling for semantic caching on that workload. The system captured most of that ceiling, but the ceiling itself is workload-dependent.
Production benchmarks compiled by ML Journey put typical cache hit rates at 30-70% across production environments, with the range depending heavily on the nature of the queries.
And then there's the reality check. Preto.ai's analysis is blunt: production data shows hit rates of 20-45%, not the 90-95% that vendor marketing pages claim. That 95% number refers to the accuracy of cache matches (when the cache fires, is the response correct?), not the frequency of hits (how often does the cache fire at all). Conflating those two numbers is how most of the inflated claims get built.
Portkey's early production tests landed around 20% hit rate at 99% accuracy for Q&A and RAG use cases. Honest, but modest.
So the range in the literature is roughly 20-70%, with the high end reserved for narrow, high-repetition workloads like customer support.
Where the Studies Fall Short
Every one of these studies measures caching on a snapshot of traffic. They take a dataset of queries, run the cache, and measure the hit rate. That's useful but it misses three things that matter enormously in production.
First, cache hit rates are not static. They improve over time. A freshly deployed semantic cache has nothing in it. Hit rate on day one is zero. As queries flow in and responses get cached, the hit rate climbs. The trajectory depends on the repetition density of the workload. A customer support system handling the same 200 question patterns will saturate its cache within days. A research agent processing novel queries will build cache slowly and see lower peak rates. But every workload follows the same curve: cold start, rapid climb, plateau. None of the studies model this trajectory. They measure the plateau.
Second, the studies don't account for deterministic routing. Semantic caching is one mechanism for avoiding LLM calls. But there's another that's even more straightforward: recognizing when a query doesn't need the LLM at all. "What's the status of order 12345?" is a database lookup. "What's my account balance?" is a structured query. A well-architected agent can route these directly to the data layer without ever touching the LLM. This isn't caching. It's just not using the LLM when you don't need it. But it contributes to total LLM call reduction and none of the caching studies include it.
Third, better retrieval quality reduces loop iterations. An AI agent doesn't make one LLM call per user query. It makes multiple calls as it loops: decide what tool to use, execute it, evaluate the result, decide again. If the context you provide to the LLM on the first pass is better (more relevant documents, more accurate vector search results, faster retrieval so you don't hit timeouts), the LLM is more likely to produce a correct tool request on the first iteration. Instead of looping five times because it kept getting partial or irrelevant context, it loops twice. That's a 60% reduction in LLM calls for that task, but it has nothing to do with caching. It's a retrieval quality story. The caching studies don't touch this.
When you stack all three mechanisms together (semantic caching + deterministic routing + fewer loop iterations from better retrieval), the total LLM call reduction is higher than what any single caching study would suggest. But you can't just add the percentages together. The mechanisms overlap and interact differently depending on the workload.
Why Hit Rates Get Better Over Time
This is the part that gets overlooked in every analysis I've read.
A semantic cache is not a fixed asset. It's a growing knowledge base. Every query that passes through the system and gets cached makes the next similar query more likely to hit. The cache doesn't just store individual responses. It builds a semantic map of the question space for that workload.
In the first week of deployment on a customer support system, you might see a 15% hit rate. The cache is learning what questions get asked. By week four, common patterns have been captured and the hit rate might be 45%. By month three, with seasonal patterns absorbed and edge cases accumulated, you could be at 60%+.
This is why snapshot studies are misleading. They measure a mature cache against a static dataset. They don't show the ramp.
The ramp matters for cost modeling. If you're projecting ROI on a semantic caching implementation, using the day-one hit rate undersells it. Using the plateau rate oversells the first few months. The honest projection shows the curve.
The other factor is cache refinement. Early implementations will have some false positives: queries that look semantically similar but actually need different answers. As you tune the similarity threshold and build exclusion rules (don't cache time-sensitive queries, don't cache personalized responses), the precision improves and the effective hit rate goes up even as the raw match rate might stay flat.
Our Framework: Stacking the Three Mechanisms
Here's how we think about total LLM call reduction for a given workload. We break it into three independent mechanisms and estimate each one separately.
Mechanism 1: Semantic response caching. What percentage of incoming queries are semantically similar to previously answered queries? This depends entirely on the repetition density of the workload. Customer support has high repetition. Novel research has low repetition. We use the published research ranges as anchors and adjust for workload characteristics.
Mechanism 2: Deterministic routing. What percentage of queries can be answered with a structured data lookup (SQL query, key-value read, status check) without involving the LLM at all? This depends on how much of the agent's job is information retrieval vs. synthesis. A monitoring agent that mostly checks thresholds and pulls status updates has high deterministic routing potential. A strategy agent that synthesizes across multiple sources has almost none.
Mechanism 3: Reduced loop iterations from better retrieval. When the LLM does get called, how many iterations does the agent loop take? And how much does retrieval quality affect that number? If your vector search returns highly relevant context on the first try (because the data is co-located with the agent and indexed in-memory), the LLM is more likely to get it right on the first or second pass. We estimate this as a percentage reduction in average loop iterations per task.
The total reduction isn't the sum of these three. It's layered: deterministic routing fires first and removes queries from the pool. Semantic caching fires next on the remaining queries. Reduced loop iterations applies to whatever's left that actually hits the LLM.
The formula looks roughly like this:
Total reduction = 1 - (1 - deterministic routing %) × (1 - caching hit rate %) × (1 - loop iteration reduction %)
This ensures the mechanisms compound without double-counting.
Our Estimates by Workload Type
Here's where we put numbers to it. These are our estimates based on the framework above, anchored to published research where possible and extrapolated where it isn't. We're showing the reasoning so you can disagree with specific inputs rather than the whole thing.
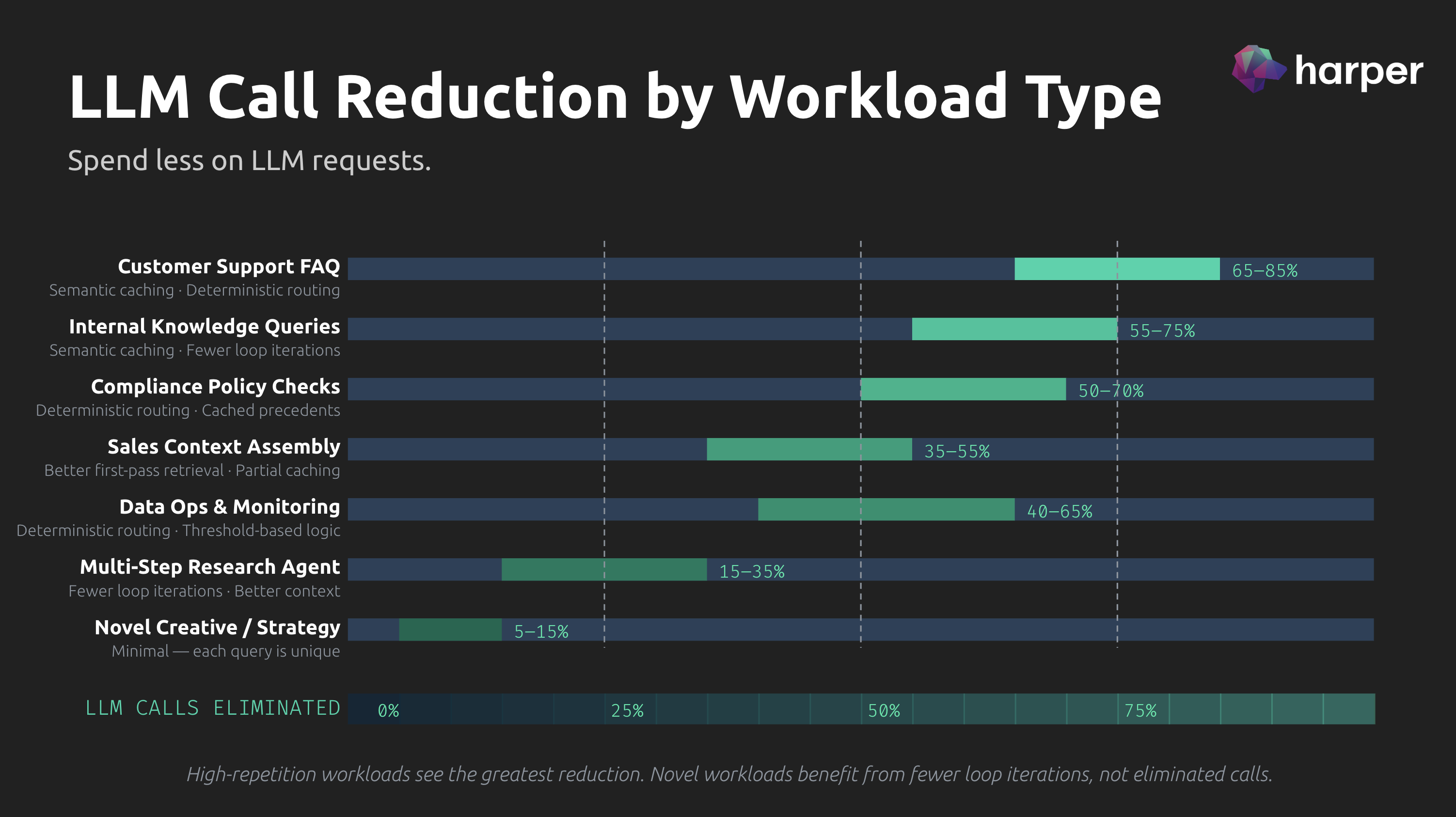
Customer Support FAQ Agents
Estimated total LLM call reduction: 65-85%
This is the highest-reduction workload. Published semantic caching studies consistently show their best results on support queries, with the GPT Semantic Cache study hitting 68.8% on caching alone for order and shipping questions. Layer on deterministic routing (a significant percentage of support queries are status checks, account lookups, and policy retrievals that don't need the LLM) and you're pushing well past 70%.
- Semantic caching: 45-60% (high repetition, predictable patterns, aligned with published ranges)
- Deterministic routing: 15-25% (account lookups, order status, policy FAQ)
- Loop iteration reduction: 10-15% (simple queries, fewer tool calls per task)
Internal Knowledge Queries
Estimated total LLM call reduction: 55-75%
Employees ask the same questions about the same processes. "How do I submit an expense report?" "What's the PTO policy?" "Where do I find the brand guidelines?" The repetition density is high and the underlying information changes slowly, which means cached responses stay valid longer.
- Semantic caching: 40-55% (high repetition, slow-changing source data)
- Deterministic routing: 10-15% (some queries are direct document lookups)
- Loop iteration reduction: 10-15% (straightforward retrieval tasks)
Compliance and Policy Checks
Estimated total LLM call reduction: 50-70%
Compliance queries cluster around specific regulations and internal policies. "Does this transaction require SAR filing?" gets asked in dozens of variations. The regulatory corpus changes infrequently, so cached interpretations remain valid. But the queries themselves can be more nuanced than support FAQs, which pulls the caching rate down slightly.
- Semantic caching: 35-45% (moderate repetition, some nuance in phrasing)
- Deterministic routing: 15-25% (threshold checks, categorical determinations)
- Loop iteration reduction: 10-15% (policy lookup is usually 1-2 steps)
Data Operations and Monitoring
Estimated total LLM call reduction: 40-65%
Monitoring agents spend most of their time checking thresholds, pulling metrics, and evaluating conditions. A large percentage of this work is deterministic and doesn't require the LLM at all. When the LLM is needed (anomaly interpretation, root cause analysis), the queries are more varied, but the data retrieval patterns are repetitive.
- Semantic caching: 15-25% (anomaly descriptions repeat, but context varies)
- Deterministic routing: 25-35% (metric pulls, threshold checks, status queries)
- Loop iteration reduction: 10-15% (well-structured data, clean retrieval)
Sales Context Assembly
Estimated total LLM call reduction: 35-55%
Sales agents pull from CRM data, competitive intelligence, pricing history, and past proposals. Some of this is deterministic (pull the account record, get the last proposal), but the synthesis step almost always requires the LLM. Caching helps when reps ask similar questions about the same accounts or competitors, but deal contexts vary enough that hit rates stay moderate.
- Semantic caching: 20-30% (some repetition in competitive and product queries)
- Deterministic routing: 10-15% (CRM lookups, pricing pulls)
- Loop iteration reduction: 15-20% (complex queries benefit most from better retrieval)
Multi-Step Research Agents
Estimated total LLM call reduction: 15-35%
Research agents process novel queries, synthesize across multiple sources, and produce unique analysis. There's very little to cache because each query is different. The primary reduction comes from better retrieval quality reducing loop iterations. If the agent finds the right documents on the first search instead of the third, that's fewer LLM calls per task.
- Semantic caching: 5-10% (minimal repetition)
- Deterministic routing: 3-5% (minimal structured lookups)
- Loop iteration reduction: 15-25% (high-iteration tasks benefit most from retrieval quality)
Novel Creative and Strategy Work
Estimated total LLM call reduction: 5-15%
Every query is unique. Every response requires fresh generation. There's almost nothing to cache, nothing to route deterministically, and the loop iterations are driven by the complexity of the task, not the quality of retrieval. This is the floor. If someone claims 60%+ reduction on novel creative work, they're either measuring something else or making it up.
- Semantic caching: 2-5% (negligible repetition)
- Deterministic routing: 0-3% (almost none)
- Loop iteration reduction: 5-10% (marginal improvement from better context)
-
What This Means
The headline claim that gets thrown around is "60-90% LLM cost reduction." That range is defensible for high-repetition enterprise workloads. Customer support, internal knowledge, compliance. If someone is running a support agent handling thousands of queries a day with a mature semantic cache and good deterministic routing, 70-80% total reduction is realistic.
But it's not a universal number. It's workload-specific. And it takes time. The cache needs to learn. The routing rules need to be built. The retrieval quality needs to be tuned.
The infrastructure matters too. Semantic caching requires vector-indexed storage for the cached responses. Deterministic routing requires the agent to have direct access to structured data without network hops. Retrieval quality depends on how fast and accurate your vector search is. If all of that lives in separate services connected by APIs, you're adding latency and complexity to the very mechanisms that are supposed to reduce cost.
If it all lives in the same runtime, co-located with the agent, accessible in-memory, that's a different story.
That's what we're building at Harper.

.webp)




.jpg)

