FEWER TOKENS
Cut LLM spend by up to 85%
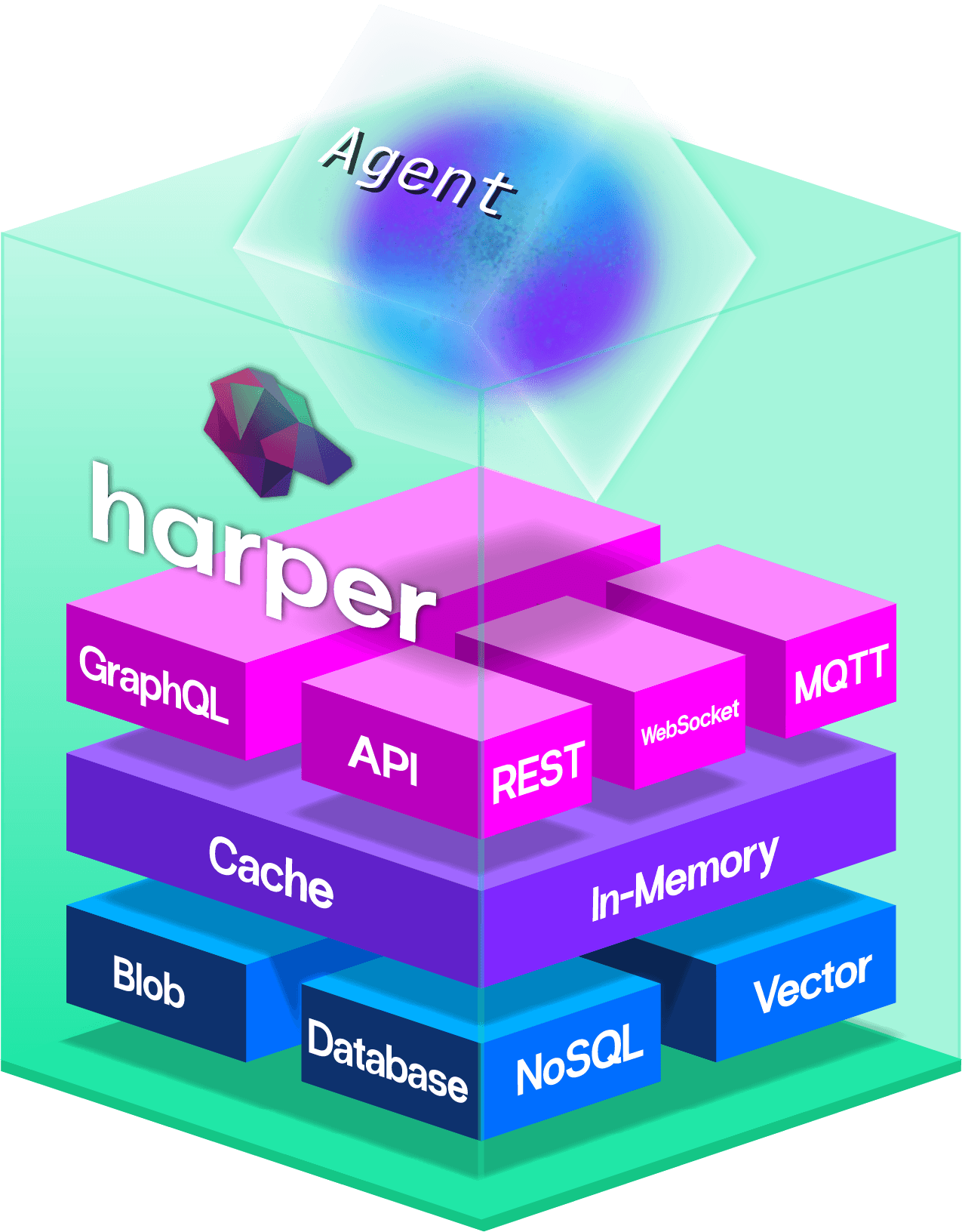
Every resolved interaction is vectorized and stored. When a similar request comes in, the runtime returns a proven answer without touching the LLM. For the rest, deterministic routing and rich context mean fewer calls and shorter loops.
SPEED
Sub-50ms context assembly
No network hops between services. No serialization overhead. Customer records, order history, vector search, and business rules queried in parallel, in the same memory space.
SECURITY
Smaller attack surface
One process, one runtime. No API keys scattered across services. No orchestration layer bridging disconnected systems. Data stays co-located, not spread across the network.
LLM FREEDOM
Don't lock into one LLM
When agents are managed separately from the LLM, the model becomes a commodity. Switch providers. Negotiate pricing. Use different models for different tasks.
EDGE-READY
Replicate everywhere
A self-contained runtime is designed for replication. Run your agent with its full data context in 2, 10, or 20 locations. Global speed, local intelligence.
SIMPLICITY
Dev to prod, same surface
What you build locally is what you deploy. One self-contained runtime. No infrastructure to wire together between prototype and production.