




I was talking to a friend over the weekend who runs a custom accessories business here in Denver. They print custom ties, bow ties, scarves, pocket squares. All made to order, all manufactured locally from recycled materials. No minimums. A single groomsman tie or a thousand-unit conference order, same workflow.
Their whole operation runs on Shopify. Orders come in through the store, customer communication flows through email and chat, design proofs go back and forth, and their small team handles everything from Pantone color matching to rush shipping for a wedding that's six days out.
Here's the thing. The volume of personalized requests they handle is staggering. Nearly every order is a conversation:
- "Can I send my own fabric and have you make it into a tie?"
- "Can you match this exact shade of burgundy from my bridesmaid dress?"
- "We need 200 ties with our company logo but the logo has a gradient. Will that print well?"
- "I ordered 10 last year for a wedding. Can we do the same pattern but in navy?"
These aren't cookie-cutter support tickets. Every single one requires context. And right now, a human is doing all of that context assembly manually: pulling up past orders, checking previous email threads, remembering how they handled a similar edge case three months ago.
So naturally, the question came up: how do you put an agent on this?
Two paths, one question
If you've prototyped an agent for customer support, you've probably started with the pattern that's fastest to demo: give the LLM access to tools via MCP or function calling, let it decide what data it needs, and have it fetch that data one step at a time.
This is the natural way to begin, because tool-calling frameworks make it straightforward. OpenAI's function calling, Anthropic's tool use, LangChain's agent loops. They all make it easy to wire an LLM to your APIs and let the model orchestrate the rest.
For the tie shop, that flow looks something like this: a request comes in. The LLM receives it. It decides it needs order history, calls Shopify's API. Gets the data back. Decides it needs to check previous conversations for similar requests, calls another tool. Comes back. Realizes it still doesn't know shipping constraints for this order size, makes another call.
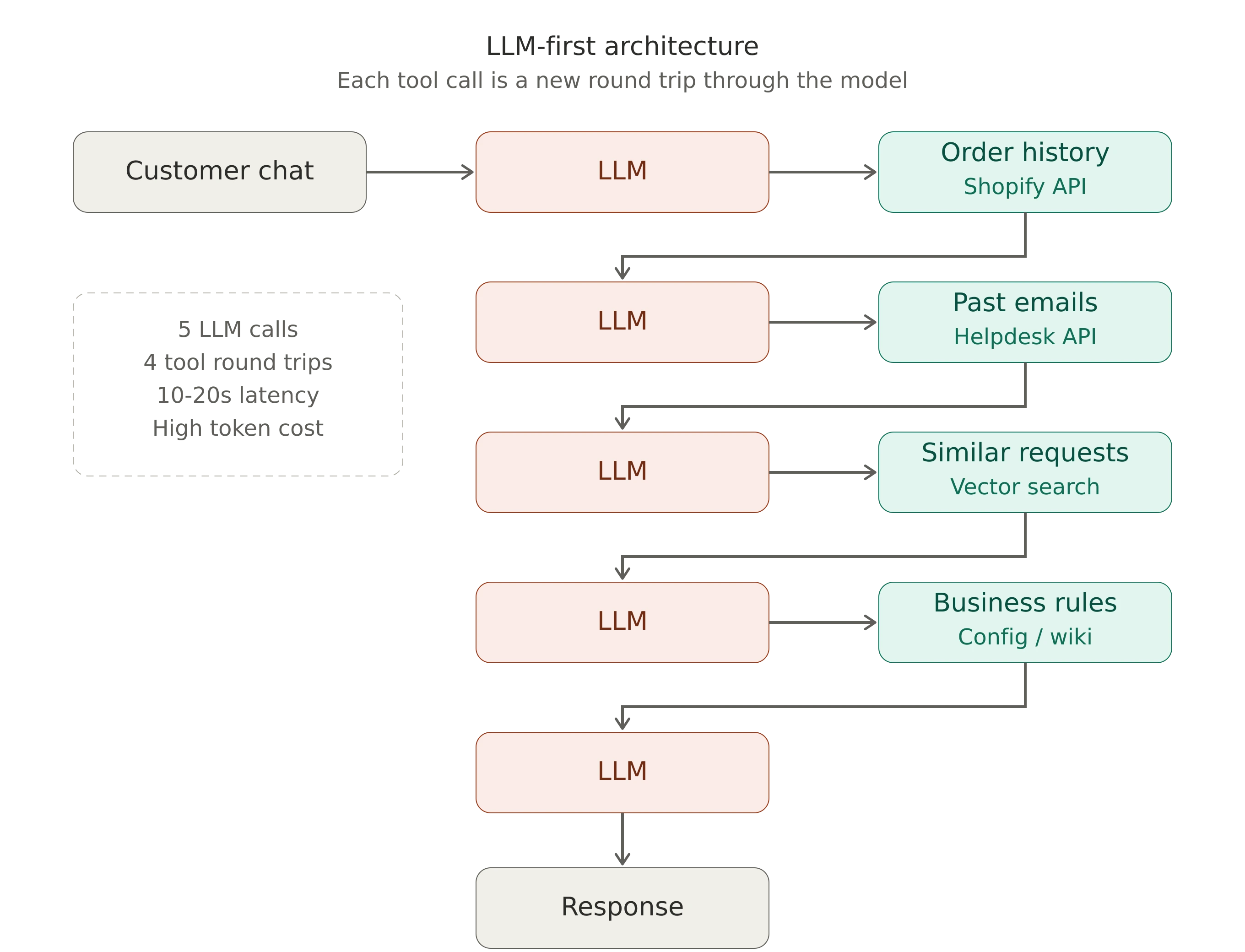
This is a valid way to prove a concept. It gets you to a working demo fast. And for simple, low-stakes queries, it can be good enough.
But teams that move this pattern toward production start hitting the same set of walls:
For a request like "I ordered custom ties last year, can we do the same pattern in navy?", the model has to sequentially figure out who the customer is, pull their history from the Shopify Orders API, find the specific past order, check pattern availability, look up turnaround times for the requested quantity, and search for any previous interactions about color matching. That's six sequential decisions, each one requiring the model to reason about what it still doesn't know. Every round trip is tokens, latency, and dollars. Every additional loop is another chance for the model to lose track of what it was doing or hallucinate a tool call.
The prototype pattern isn't wrong. It's incomplete. And the teams moving from demos to production are already reorganizing their systems around a different question: how much of this work can happen before the model is ever invoked?
Context-first: the production pattern
The industry is converging on this. Anthropic's own guidance on building support agents frames chat as a bundle of tasks that includes information retrieval and action-taking, and it directly notes that the model may need relevant information in context, potentially through RAG. LangGraph's entire positioning is built around long-running, stateful agents with durable execution and memory, not thin prompt wrappers around a model. The direction is clear: serious implementations treat context assembly as an explicit design concern, not something the model should figure out on the fly.
So what does context-first actually mean in operational terms?
It means that deterministic work happens before the model is invoked. When a message arrives, the first thing that should happen is not an LLM call. It's a set of parallel data operations:
Identify the customer. The message came from an email or a logged-in session. Pull their full profile, order history, and any previous interactions. This is a database query, not an LLM decision. If you're on Shopify, the Customer API gives you everything tied to that email.
Semantic search over past conversations. Take the inbound message, vectorize it, and search against previous support interactions that have been resolved. How did the team handle "can I send my own fabric" last time? What was the answer on gradient logos? This is a vector similarity search, not a reasoning task.
Retrieve active order state. If they have an open order, pull the design proof status, production timeline, shipping details. All structured data sitting in your system via the Shopify Fulfillment API.
Check business rules. Turnaround times by order size, rush pricing, current production capacity. These are lookups, not inferences.
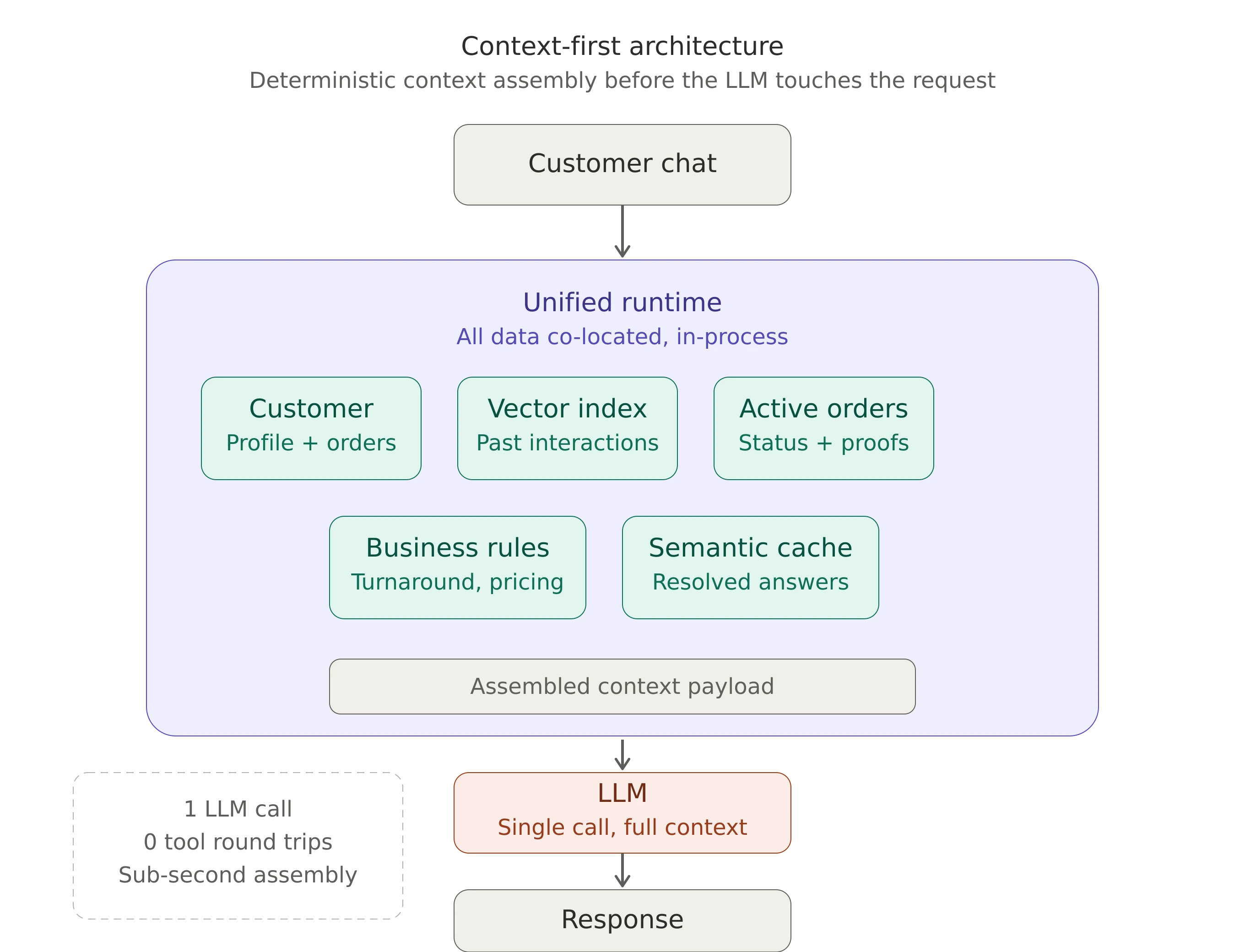
By the time the LLM receives the request, it's not starting from zero. It has the customer's history, semantically similar past interactions with resolved answers, active order context, and the relevant business constraints. One call. Full context. Clean response.
The difference isn't marginal. You go from five or six round trips to one. Token usage drops. Response time goes from "agent is thinking..." for 15 seconds to something that feels near-instant. And the quality improves because the model isn't stitching together fragments it collected piecemeal. It's reasoning over a complete picture. The model does what it's genuinely good at: thinking and writing over complete information, not exploring, searching, and orchestrating.
This is a runtime problem, not a model problem
The operational definition of context-first is clear enough. The architectural question is where that context assembly happens.
If your order data lives in Shopify, your conversation history lives in Shopify Inbox or a helpdesk like Gorgias, your resolved interactions are buried in email threads, and your business rules are scattered across a wiki, then assembling context means orchestrating calls to four or five separate systems before the LLM is ever invoked. You've moved the work out of the model loop, which is good. But you've replaced it with a fragile integration layer stitching together network calls to disconnected services. Every additional source of context is another API to maintain, another failure point, another chunk of latency.
This is where the real pain lives. Not in writing the first webhook or crafting the initial prompt. The pain is in maintaining reliable, fast, parallel access to structured data, support history, vector search, and business logic across products and services that were never designed to work together.
The more natural architecture is one where all of that data is co-located: customer records, transaction history, vector-indexed conversation logs, and business logic, all accessible within the same process. No network hops between services. No serialization overhead. No orchestration layer deciding which system to query next. Context assembly becomes a set of local, in-process operations that execute in parallel, in milliseconds.
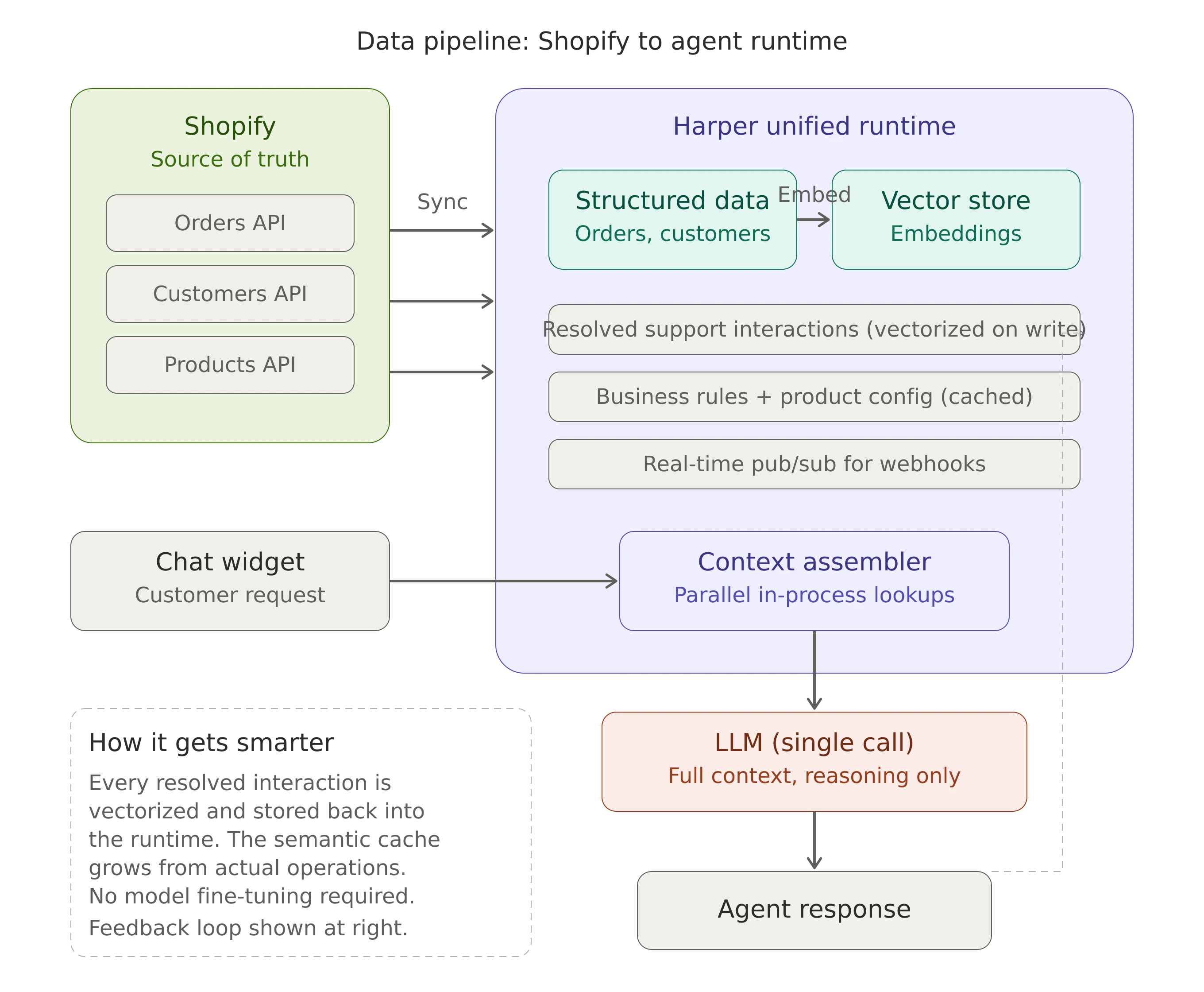
This is what a unified runtime gives you. An operational context layer that collapses structured data, semantic memory, and business logic close to the agent path. The database query, the vector search, the cache lookup, they all happen in the same memory space.
And the effect compounds. When every resolved interaction gets vectorized and stored back into the same system, your agent gets smarter over time without any model fine-tuning. The semantic cache of "how we've handled this before" grows organically from actual business operations. New edge cases get absorbed the moment a human resolves them.
What this looks like at the Shopify scale
For a business running on Shopify, the implementation path is more concrete than you might think. Shopify's APIs expose everything you need: orders, customers, products, fulfillments, draft orders. The data is there. The question is where you put it so your agent can use it efficiently.
Step one: Sync your Shopify data into a runtime that supports both structured queries and vector search. Customer records and order history come in as structured data. Every resolved support interaction gets embedded and stored as vectors alongside the structured records they relate to. Shopify's webhook system keeps this in sync as orders are created, updated, and fulfilled.
Step two: Build your agent's pre-LLM pipeline. When a request comes in, the runtime handles context assembly: customer lookup, semantic search, order retrieval, business rule checks, all in parallel, all local. The output is a single, rich context payload.
Step three: Send that payload to the LLM as a single request. The model's job is now purely reasoning and language generation. Not exploring, not searching, not orchestrating.
Today, this is practical to build and ship with tools like Claude Code, Shopify's APIs, and a runtime that supports both structured data and semantic retrieval. What used to require a platform team can now be assembled by a non-technical entrepreneur. Here's a prompt to start with:
I want to build an agentic customer support system for my Shopify store using
Harper as the unified runtime. Here's what I need:
1. A Harper schema that stores:
- Customer records (synced from Shopify Customers API)
- Order history (synced from Shopify Orders API)
- Support interactions (with vector embeddings for semantic search)
- Business rules (turnaround times, pricing tiers, escalation thresholds)
2. A Shopify webhook listener that syncs new orders and customer updates
into Harper in real-time.
3. A context assembly function that, given an inbound customer message:
- Identifies the customer by email
- Retrieves their full order history
- Runs a vector similarity search against past resolved interactions
- Pulls any active/open orders
- Assembles all of this into a single context payload
4. An agent endpoint that takes the assembled context + the customer message,
sends it to Claude as a single prompt, and returns the response.
5. Escalation logic: if vector search confidence is below 0.7 or order value
exceeds $500, flag for human review instead of auto-responding.
My Shopify store URL is [YOUR_STORE].myshopify.com and I have an Admin API
access token ready. I want to deploy this on Harper Fabric.
Start with `npm create harper@latest` and build from there.
The challenge is no longer whether you can wire it together. The challenge is whether you can design the retrieval, memory, escalation logic, and evaluation path well enough for production. That's the work that separates a demo from a system customers trust.
The key resources you'll want bookmarked:
- Harper documentation for schema design and vector search
- Shopify Admin API reference for the data sync
- Shopify webhooks guide for real-time updates
- Claude API documentation for the LLM integration
- MCP specification for tool/server patterns
- Anthropic's customer service agent guide for retrieval and escalation design
When the agent should step aside
One thing my friend asked that I think a lot of teams skip: when should the agent bring a human in?
This is actually easier to solve when you have rich pre-assembled context. You can set deterministic thresholds before the LLM is ever involved:
- Low confidence: If the semantic search returns no similar past interactions above a confidence score, escalate. The agent doesn't have a precedent to work from.
- High value: If the order value exceeds a threshold, escalate. A 1,000-unit corporate order deserves a human touch.
- Negative history: If the customer has had a previous negative experience flagged in their record, escalate. Don't let the agent fumble a recovery.
- Novel edge case: "Can I send my own fabric?" might have zero semantic matches. That's a flag, not a failure.
These aren't LLM judgment calls. They're business rules evaluated against structured data. The agent doesn't need to "decide" if it's out of its depth. The system knows, because the context tells it.
The enterprise version of the same problem
The reason I'm writing about a tie shop and not an enterprise retailer is because the pattern is easier to see at small scale. But the architecture is identical for a company processing millions of orders, and the economic argument gets stronger, not weaker.
The more fragmented the operating environment, the more expensive the LLM-first pattern becomes. A small brand running on Shopify feels the cost as latency and awkward support loops. A large retailer pulling from an ERP, a warehouse management system, a CRM, a returns platform, and a loyalty program feels it as orchestration overhead, integration complexity, and unpredictable costs that scale with every additional data source.
If you're at that scale, the Shopify APIs in the examples above become your internal service APIs. The pattern is the same: sync everything into a single runtime so context assembly is local and parallel. The tools are the same: Harper handles structured data, vector search, caching, and real-time pub/sub in one process. The deployment is the same: Harper Fabric runs at the edge, close to your users.
The unified runtime pattern scales in the opposite direction from the LLM-first approach. The more data you co-locate, the faster your context assembly gets. The more interactions you vectorize, the better your semantic cache becomes. The more deterministic work you pull out of the model loop, the more predictable and cost-effective your agent becomes.
What this really comes down to
The shift happening in agent design right now is from model-centric systems to runtime-centric systems.
The LLM is stateless. Every call starts from nothing. The quality of its output is entirely determined by what you put into the prompt. Most early agent architectures treated context assembly as something the model should figure out on its own through tool use. But that's asking a stateless system to manage state, which is the exact thing it's worst at.
The teams building agents that actually work in production have already internalized this. They're moving context assembly out of the model's loop and into the runtime layer. Let the runtime hold state. Let the runtime understand relationships between data. Let the runtime handle the deterministic work of gathering everything the model needs. Then let the model do what it's genuinely exceptional at: reasoning over complete information and generating a thoughtful response.
The model is still important. But it should not be responsible for gathering its own world state. The faster teams arrive at that conclusion, the faster they build agents that are reliable, cost-effective, and good at the edge cases that actually matter.
Start with npm create harper@latest and check out the docs. The source is open, and the community is a good place to talk architecture.

.webp)




.jpg)
