




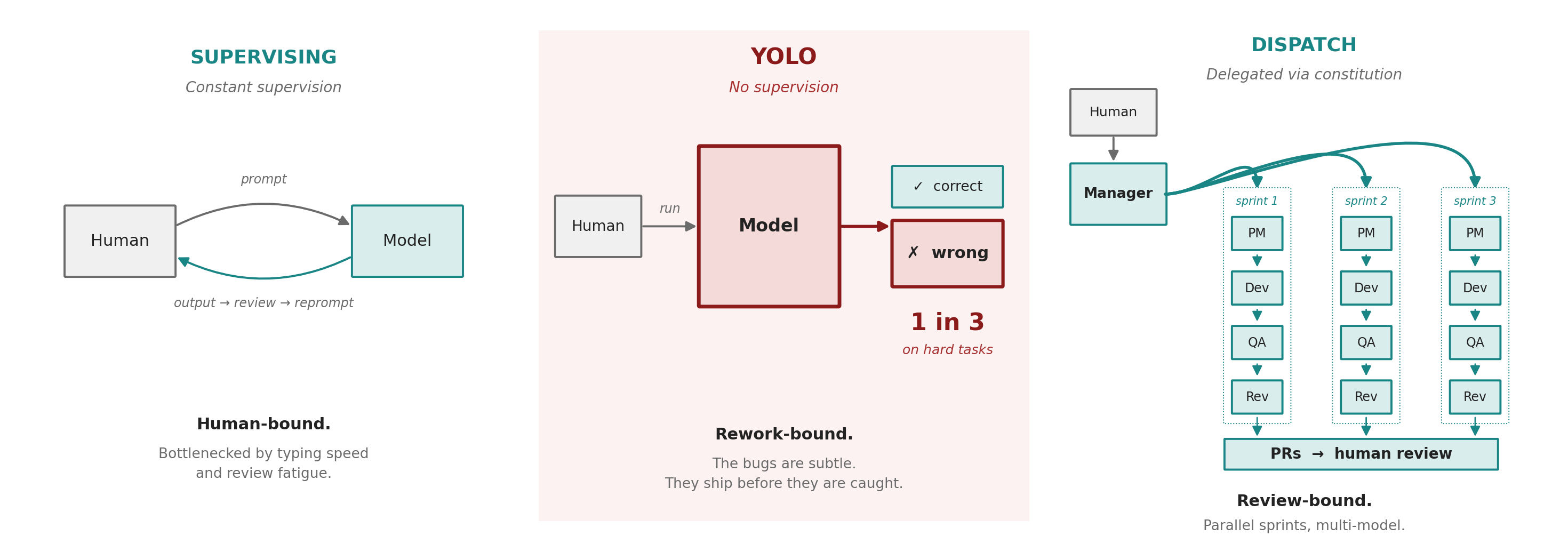
Until recently, working with a coding agent meant sitting in front of a terminal and feeding it one prompt at a time. The model proposes. The human reads. The human clicks accept. The loop is bounded by how quickly the human can read and judge. The alternative was to remove the permissions and let the agent run unsupervised, which produced poor quality code. As of May 2026, the unsupervised single-model error rate on real engineering work sits between roughly one in eight and one in three, depending on task difficulty. Any engineer shipping at a one-in-three failure rate would be fired. An agent shipping at that rate on your behalf is the same liability, automated.
This is the gap between vibe coding and agentic engineering. Vibe coding produces prototypes. Agentic engineering produces production code. This is not another article about vibe coding.
Production quality is achievable at vibe code velocity, with the right stack and the right process.
The team I lead is no longer waiting on me to type. Last Friday, that team shipped five pull requests against a customer engagement while I slept. I reviewed them from bed on Saturday morning and dispatched the next round before getting up.
Why a collapsed stack changes what the agents spend their time on.
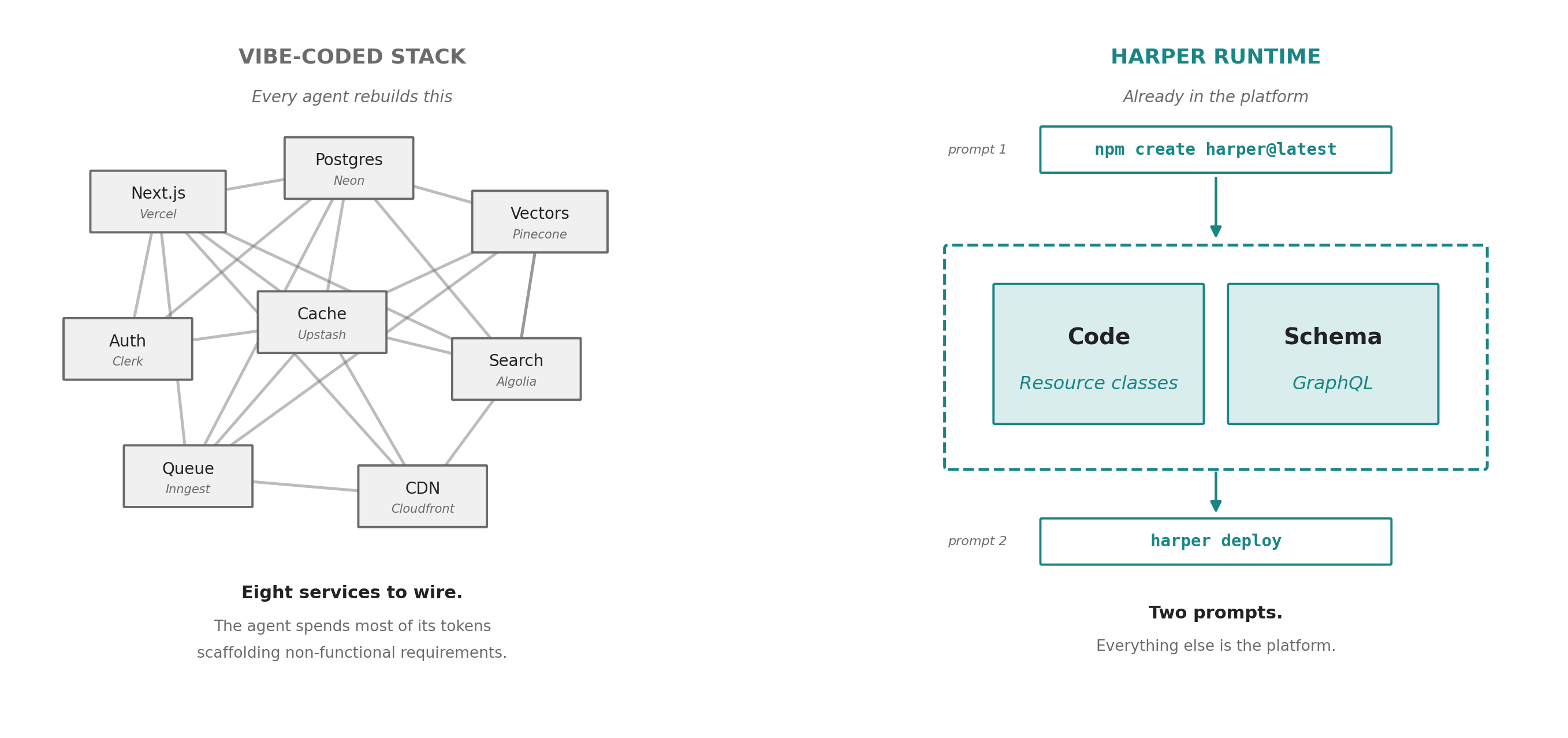
Most agent built applications end up with a similar shape: a Next.js app on Vercel, a database on Supabase, a cache on Upstash, a vector store on Pinecone, an auth service on Auth0, a search index on Algolia, a queue on Inngest, and a CDN configuration on Cloudflare. Each piece is reasonable on its own, but the composition is not. Agents are good at writing code, and are bad at stitching together the services required to host that code. The agent spends most of its tokens building and rebuilding the infrastructure rather than building your application.
Harper collapses that infrastructure. The database, the cache, the API layer, and the application runtime all live inside the same Node.js process. The agent does not write a Pinecone client and a Redis client and a Postgres client. It writes a Resource class against a table, and the same table is the cache, the search index, and the live data source.
// --- Semantic cache resource ---
export class QuestionAnswer extends Resource {
static async get(target) {
const rawQuestion = target.get('q');
if (!rawQuestion) {
const error = new Error('Missing required query parameter: q');
error.statusCode = 400;
throw error;
}
const question = rawQuestion.trim();
// 1. Embed the incoming question
const queryEmbedding = await embed(question);
// 2. Search the HNSW index for the nearest cached answer
const results = tables.QuestionAnswer.search({
sort: { attribute: 'embedding', target: queryEmbedding },
limit: 1,
select: ['id', 'question', 'answer', 'generatedAt', 'embedding', '$distance'],
});
This changes the math on agent productivity in two ways. The agent finishes each task faster because it stops scaffolding non-functional requirements. And the code it produces is higher quality, because the surface area is small and uniform.
Without a collapsed stack, dispatching ten agent teams in parallel produces ten different architectural decisions. With it, ten teams produce ten easily reviewable features.
The team and the multi-model dispatch.
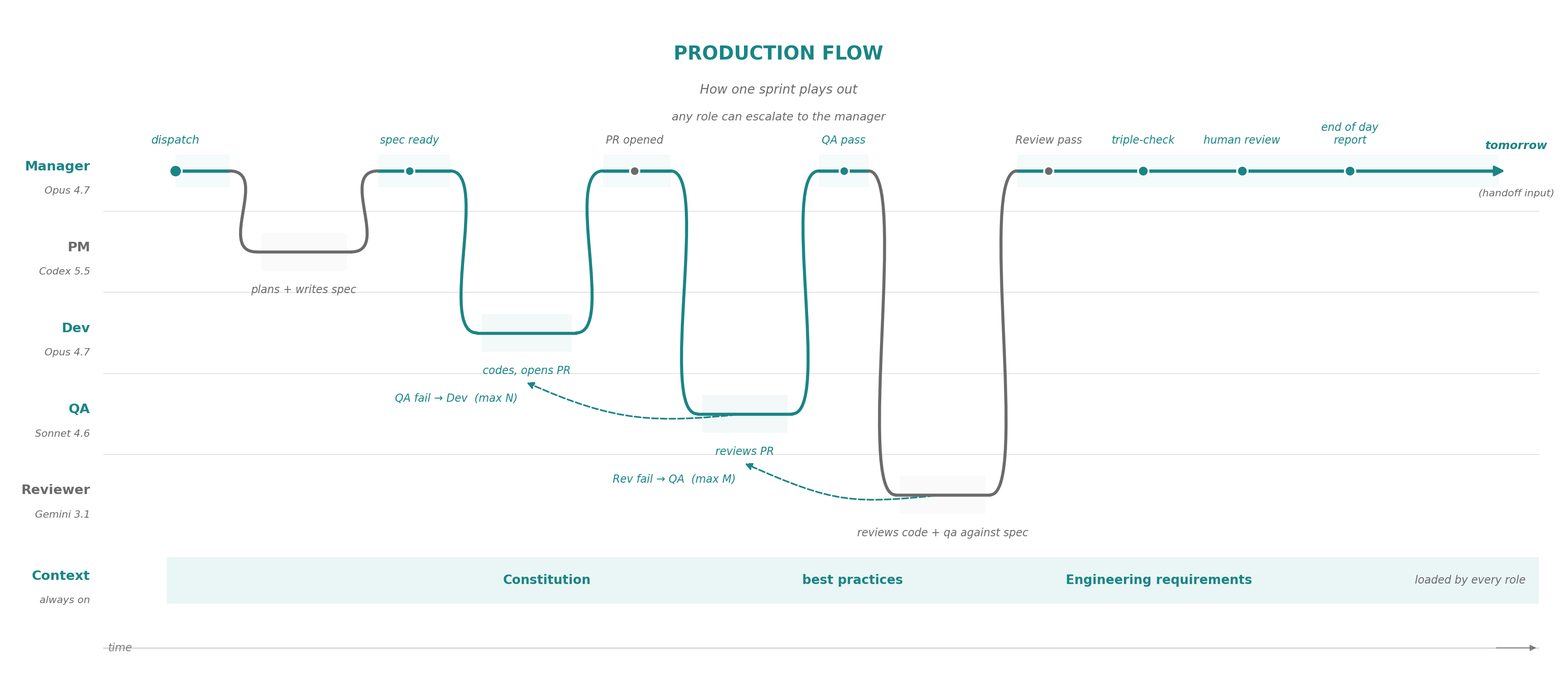
The team has five roles, each pinned to a specific model and run as a subagent of the sprint orchestrator. The model for each role is selected based on what leads against the benchmark. Three months from now the same five roles may run on different models, and the architecture will not need to change to absorb that.
"Read an issue and produce a tight, well-structured spec" is GPT's strongest play, so Codex draws the PM planner. "Read a spec and write code that matches it" is Opus's strongest play, so it draws the developer. "Follow a spec literally and read code against it" is Sonnet's strongest play, because it follows instructions more precisely than Opus while keeping Claude’s coding skills, so it draws the adversarial QA role. "Read the whole change in one pass and catch what the same-lineage pair would have rationalized away" is Gemini's strongest play, so it draws the adversarial reviewer role. This is the leaderboard model assignment as of May 2026.
The Manager runs Opus as a long-lived Claude Code session. It reads the GitHub backlog every morning, picks the issues for the day, and dispatches the sprint agents in parallel in separate branches and worktrees. It holds the constitution, resolves cross-sprint conflicts, and escalates to the human only when a decision requires authority it does not have.
## Phase 1 - Survey and Plan
Gather current state:
```sh
DEFAULT_BRANCH=$(gh repo view --json defaultBranchRef -q
.defaultBranchRef.name)
gh issue list --state open --limit 50 --json
number,title,labels,createdAt,updatedAt,body
gh pr list --state open --json
number,title,headRefName,baseRefName,updatedAt,body
git log --oneline -20
~/.claude/scripts/sprint-team.sh preflight
```
Also read:
- `CLAUDE.md` if present
- `~/.claude/team-runs/daily-log.md` if present
The PM reads the issue, the linked code, and the constitution. It writes the spec to a file. The Developer reads the spec, writes the code, and opens a draft pull request. Reading only the spec keeps the developer narrow. The QA agent is adversarial. Given the spec and the diff, its only job is to find ways the code does not satisfy the spec or does not actually function. Failures route back to the Developer with the QA report attached to the PR. The Manager can loop developer-QA cycles up to a configured cap. The Reviewer is again adversarial, but pointed at the whole change. It runs only after QA has cleared.
The constitution, the escalation, and the anti-forgery rule.
The team operates under a constitution. Every role loads it as the first context block. It defines what the team is allowed to decide on its own and what it has to escalate.
## Decision Authority
Agents own HOW:
- File selection after investigation
- Implementation strategy
- Test design
- Refactoring needed to complete the assigned change
- Tool choice and local troubleshooting
The engineering manager owns bounded WHAT/WHY interpretation:
- Choosing a conservative reading of an ambiguous issue
- Picking the smaller reversible scope
- Sequencing or deferring work
- Resolving conflicting agent recommendations when the codebase or issue thread gives enough evidence
- Recording decisions on the issue or PR for later stages
The user owns only decisions that cannot safely be delegated:
- Merge, approval, deploy, destructive git, or production action
- Credentials, billing, account access, quota purchase, or external service ownership
- Product intent that is not stated in the issue/spec/comments/codebase
- Public API, data model, migration, security posture, or irreversible behavior changes
- A repeated infrastructure failure after automated recovery is exhausted
When a subagent hits a question it cannot answer, it stops and escalates up one level. The level above resolves if it can. The Manager has more autonomy than the subagents and resolves most issues. When it cannot, it surfaces the decision to the human. Escalations reach me through Claude remote control, the mobile interface to the Claude Code CLI session. Read, decide, dispatch, all from the phone.
The other rule the constitution enforces is anti-forgery. When a step requires invoking a model in a different family, the calling agent must actually invoke that model and read the response. It is not allowed to predict, synthesize, or summarize what the other model would have said. This sounds obvious, but is not a default behavior. A Claude agent under context pressure will happily reconstruct what Codex or Gemini "probably" said. The constitution forbids it, and a verification script catches the forgery when it happens anyway by checking that the Codex and Gemini transcripts are real artifacts with valid timestamps. Adversarial review only works if it is actually adversarial.
Scripts for certainty. Prompts for judgment.
The verification surface inside a sprint is split between two kinds of work.
Code generation, spec interpretation, and adversarial review are LLM jobs. They tolerate the per-model error rate because three different models in three different families have to agree before a PR is ready for review. The compounding is what gets the team above the single-model noise floor.
Everything else is a script with a deterministic exit code. None of these are LLM judgments. The agents run them and read the exit codes.
if ! jq -e '
type == "object"
and .tool == "gemini-review"
and (.head_sha | type == "string" and length > 0)
and (.model | type == "string" and length > 0)
and (.comment_id | type == "number")
and (.comment_sha256 | type == "string" and length == 64)
and (.verdict == "RECOMMEND_MERGE" or .verdict == "CHANGES_NEEDED")
' "$integrity" >/dev/null; then
echo "integrity-invalid"; exit 1
fi
This is the second half of the anti-forgery rule. A model under pressure will say the tests passed when the tests did not even run.
Scripts encode the rules nobody is allowed to break. Prompts encode the judgments somebody has to make.

Harper makes the script half cheap because the sandbox is one process and the schema is one file. The agent does not have to spin up infrastructure to verify that its code works against the platform it is going to ship on.
What it looked like last Friday.
Our customer is a national apparel retailer running its storefront on Harper, preparing a major application upgrade. They needed an end-to-end audit of the current code base and a detailed upgrade plan created. Friday afternoon I asked the team to do the audit and propose the plan.
The output was twenty-three GitHub issues, each scoped at roughly one sprint, ranging from configuration changes to non-trivial refactors of the search and personalization surfaces. I read the issue list on my phone over dinner, made a few edits, and started the engineering manager. I went to bed.
The manager dispatched sprints in parallel across the issues that did not have dependencies. The dependent issues waited in a queue. Each sprint ran the four-role pipeline. Most sprints passed QA on the first attempt. A handful went through one or two rework loops. Two failed the Gemini reviewer and were held for the human, which the manager flagged in the morning briefing it wrote for my review.
Saturday morning I read the briefing on my phone, opened the five clean pull requests in GitHub Mobile, and reviewed them in bed. Three were merged as written. Two needed comments. I asked the engineering manager to redispatch against my comments through Claude remote control, and went to make coffee. By the time I sat down at the laptop, the remaining two sprints had cleared review.
The audit and the migration plan that would have taken a senior engineer the better part of a week were drafted, reviewed, and shipped in under 14 hours. I typed approximately one hundred and twenty words across the whole exercise. The team did the rest.
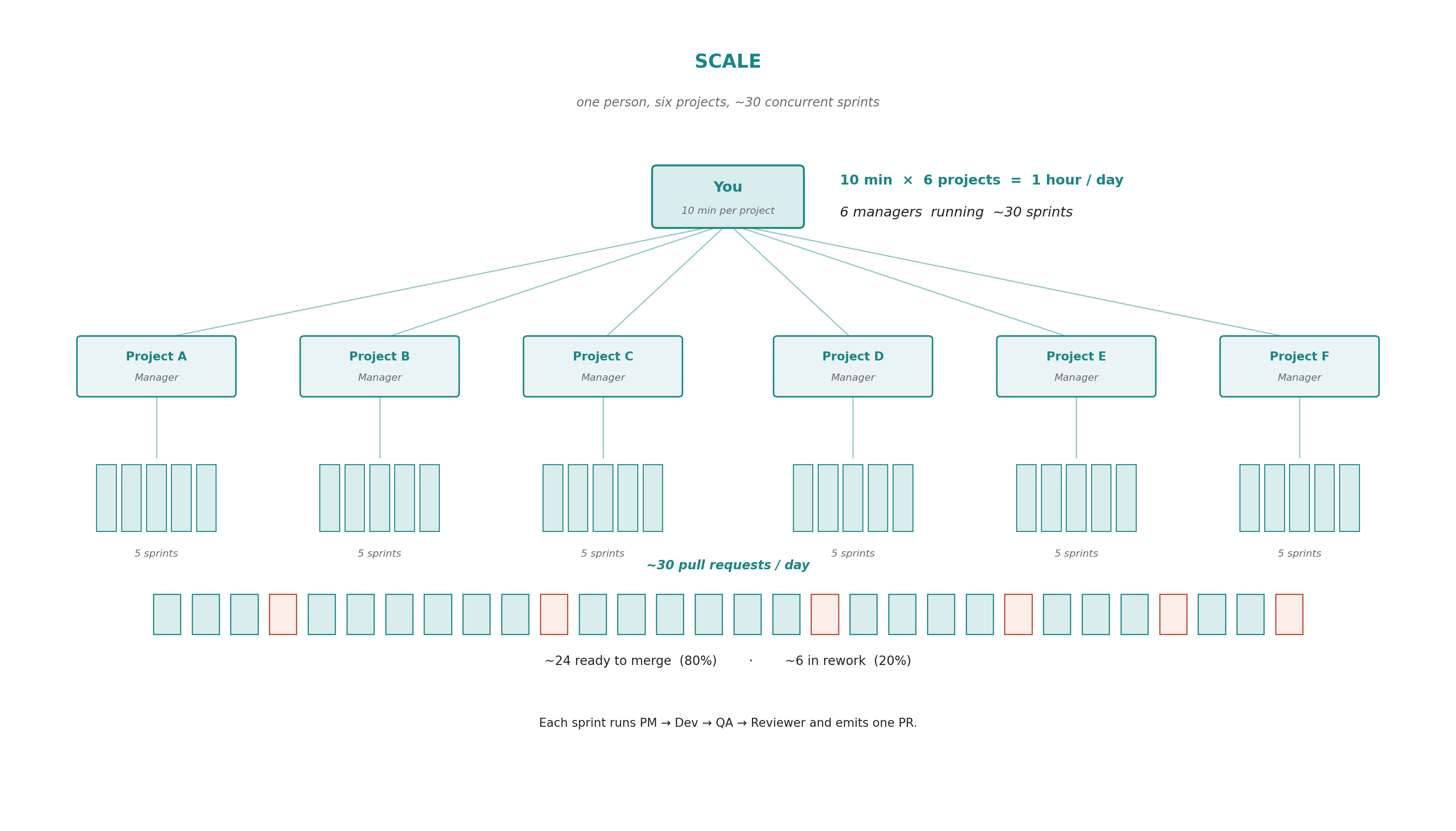
Scaling to multiple projects.
I do not run the team one project at a time. The pattern scales sideways the same way it scales upward: a fresh engineering manager session per project, ten minutes of human attention each morning to set the day, and the rest is dispatch. The current loadout is six concurrent projects, roughly an hour of my time a day to operate them.
Isn't this just spec-driven development?
Spec-driven development is the foundation. Superpowers, Spec Kit, and other workflows are related. None of these are wrong, necessarily, but, none of them are what is being described here either.
Spec-driven development gets the substrate right. Write a tight spec, hand it to an agent, review the result. Every role on this team uses SDD principles inside its lane. What SDD does not address is who reads the PR, when, and at what scale. The published SDD frameworks assume one developer, one agent, one project, watching each task as it lands. There is constant supervision of the agent.
Subagent-driven development goes a step further. Superpowers dispatches fresh subagents per task with two-stage review, and the orchestrator manages many of them from one main session. But subagents live inside a single Claude Code session, use a single model family, and end when the session ends. The reviewer is another Claude critiquing Claude. The v5.0.6 release of @obra/superpowers even removed the subagent driven development as standard, because it recognized that single model review, even via subagents, only added time and did not improve code output quality.
The contrast:
Three things sit on top of that foundation. Persistent manager sessions per project, not subagents inside one terminal. Different model families as adversarial gates, not the same model critiquing itself. Aggregate PR review on a phone, not interactive supervision at a desk. None of these pieces are new alone. What is more rare is documented production work running this way against customer engagements, with measured pass rates and a published assembly.
Agents shipping production ready applications.
This same pattern can be used by any Harper developer to ship code, agents, and applications. A team built this way produces production ready Resource classes, MCP servers running as Harper components, MQTT pub/sub handlers for agent coordination, and semantic cache layers for LLM applications. The team is using agents to ship production ready agentic applications.
A developer who watches this team work and asks "could I have one of these" is asking two questions at once: can I run an internal development team like this, and can I ship an agent-powered feature that operates like this for my own users? The answer to both is yes, and the answer is yes for the same reason: Harper is one process with the runtime, the data, the cache, the broker, and the application in it.
A single human in a chat session clicking accept is bound by typing speed and review fatigue. An unsupervised agent yolo-ing into a Lovable app is bound by errors and rework.
The dispatching pattern gets above both ceilings. It works because Harper makes the substrate small enough for the team to reason about and small enough for the human to review. The human decides what to build and why. The team decides how. A runtime lets them do product work. Harper is the runtime.

.webp)


.jpg)




