




A CDC event can be a payload or a trigger. Most destinations only handle the first kind. Harper handles both — and the trigger case, where the runtime supplies the workflow, is where it earns its place.
CDC is the standard. The destination is the architecture decision.
Most teams have settled on change data capture for keeping downstream systems in sync with their source of truth. The pattern is mature. The architecture question is not whether to do CDC. The architecture question is what the CDC stream lands in.
Three common destinations are wrong for serving applications. A data warehouse (Snowflake, BigQuery, Databricks) is built for analytics, not serving. It cannot render a page or assemble agent context in milliseconds. A message queue (Kafka, Pub/Sub) just forwards the problem to the next consumer. A CDN cache (Fastly, Cloudflare, Akamai) holds the data as URL-keyed blobs, none of which are queryable.
The fourth destination is a runtime that holds the data in the same shape the source did, can serve it directly, can run application logic next to it, and can replicate it natively across regions. That is Harper.
Calling Harper a destination understates what it does. CDC events come in two flavors. A payload event carries the new state — the consumer upserts it and stops. A trigger event carries a notification — the consumer is expected to do something with it. A warehouse, queue, or CDN can handle payload events; that is the standard CDC pattern. None of them can handle trigger events, because none of them have a runtime to do the work. Harper can handle either, because it does: query the cache by any indexed field, recompute affected entries, fan work out to in-process workers, replicate the result. The runtime supplies the logic.
The rest of this piece is about what that looks like in production, why the same pipeline serves pages and AI agents, and where the architecture goes if you run it long enough.
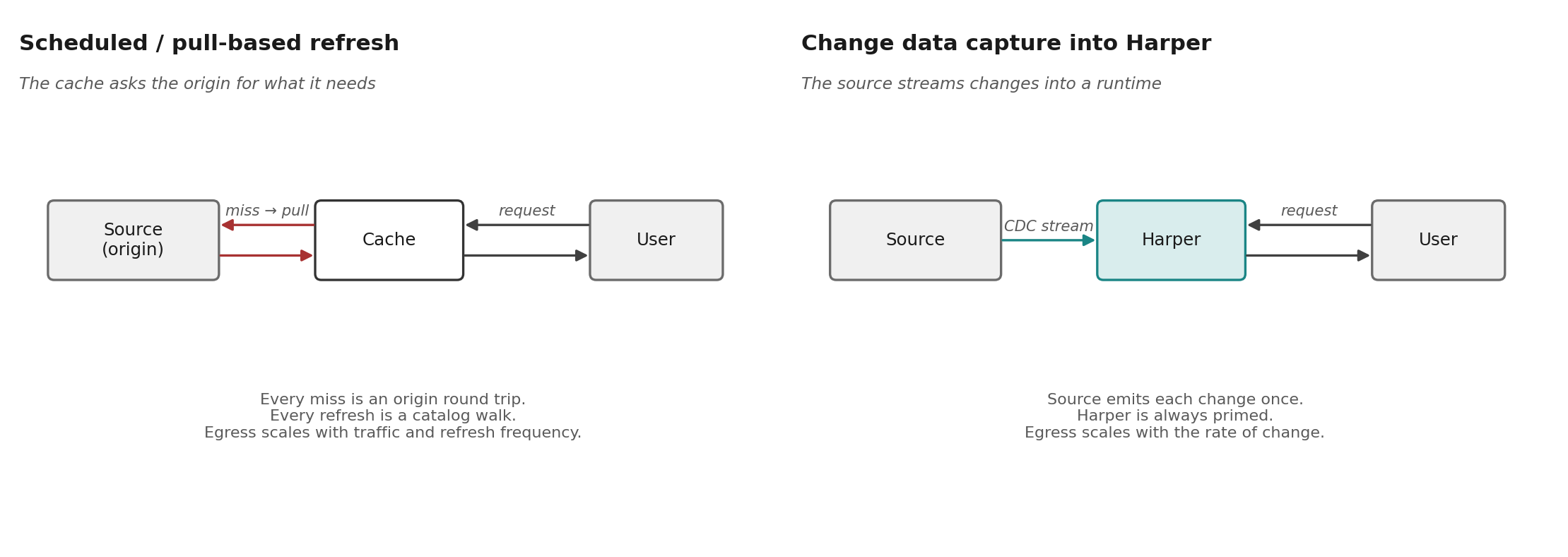
Why scheduled refresh stops working
The case for CDC starts with what it replaces. Scheduled refresh — a job that pulls from the source on a clock and writes to the consumer — works for one consumer and a small data set. Most organizations have outgrown both. They now have many consumers (page caches, search indexes, recommendation engines, customer service agents, LLM context stores) reading large catalogs. The architecture that scaled for one small consumer does not scale to ten large ones.
A retailer with ten million SKUs cannot pull-refresh the catalog every hour. The egress cost is prohibitive. The origin cannot sustain the read load. A one-hour staleness window does not survive contact with merchandising.
A retailer with ten thousand SKUs can do it, but only by absorbing three costs: an egress bill that scales with refresh frequency, an origin sized to handle refresh storms in addition to user traffic, and a staleness window the business will eventually stop accepting.
CDC removes all three. One event per change, regardless of catalog size. The origin is sized for writes, not for refresh reads. Freshness is bounded by event propagation, which is seconds.
At production catalog size, you do not refresh the whole catalog on a schedule. The math does not work. You refresh exactly what changed, exactly when it changed. The CDC event tells Harper which entries are affected; the workflow inside Harper recomputes only those entries. Pages stay fresh because the right ones get re-rendered the moment they need to, not because the whole catalog got rebuilt overnight.
What CDC into Harper looks like in production
A top-five US department store streams product change events from its upstream ERP into Harper via GCP Pub/Sub. In this case the events are triggers rather than payloads: they carry the product IDs that changed, not the new product data. Each one kicks off a workflow inside Harper: the subscriber queries the page cache by resourceId for every entry the changed products appear on, patches each match to schedule a re-render, and the render workers in the same runtime consume the resulting queue and write fresh HTML back. Time between an upstream change and the customer seeing the new page: minutes, not hours.
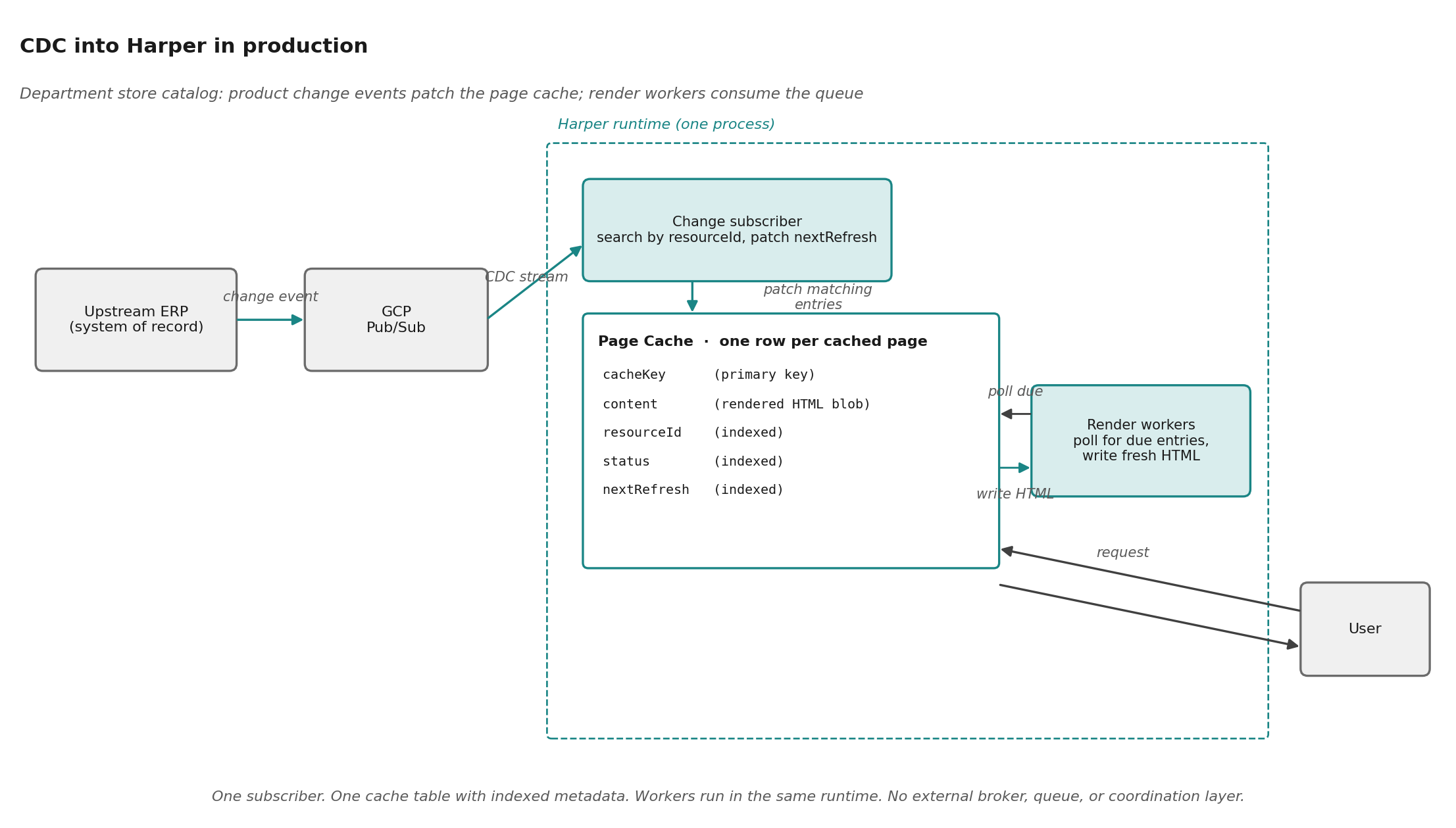
The Harper side is small because the cache, the queue, the workers, the search index, and the request handler all live in one runtime. A table declared in schema.graphql is simultaneously a topic, a REST endpoint, a search-indexed store, and a replication source.
type Cache @table @export {
cacheKey: String @primaryKey
content: Blob
statusCode: Int
url: String
resourceId: String @indexed # product ID, for CDC matching
status: String @indexed # 'scheduled' | 'completed' | ...
nextRefresh: Long @indexed # workers poll on this
}
const sub = pubsub.subscription(subscriptionId);
sub.on('message', async (message) => {
const { resourceIds } = JSON.parse(message.data.toString());
// Find every cached page affected by these products
const matches = await pageCache.search({
operator: 'or',
conditions: resourceIds.map(id => ({
attribute: 'resourceId',
comparator: 'equals',
value: id,
})),
select: ['cacheKey'],
});
// Bump them to the front of the render queue
for await (const { cacheKey } of matches) {
await pageCache.patch(cacheKey, {
status: 'scheduled',
nextRefresh: Date.now() + 2 * 60 * 1000,
});
}
message.ack();
});What is not in this code is just as instructive. No explicit deduplication. No coordination between handlers. No separate broker, no separate cache, no separate queue, no separate search index. Setting a cache entry's nextRefresh is naturally idempotent: running the handler twice produces the same state. The runtime handles the work that would otherwise be wired across four different systems.
Source to source, not source to cache
The advantage Harper has over the other CDC destinations is that it speaks database to database. A CDN cache knows about cache keys, TTLs, and origin URLs. A queue knows about offsets. A warehouse knows about analytical schemas. Harper has tables, columns, types, indexes, and replication.
Look back at the department store example. The page cache is not just a content store keyed by URL. Every entry has a resourceId index (the product the page is about), a status index (where the entry is in its render lifecycle), and a nextRefresh index (when it should be re-rendered). When a product change event arrives, the subscriber can ask the cache a question a CDN cannot answer: "find every entry tied to this product." It patches nextRefresh on each match in place, and the workers do the rest.

This is what makes CDC into Harper operationally different from CDC into a CDN. The CDN holds opaque blobs keyed by URL. Harper holds the blob plus the structured metadata around it, addressable by any indexed field, updatable in place. Every consumer (pages, search, agents, semantic caches) can read and write through the same table.
Once data lands on one Harper node, native replication carries it across the cluster. This is where most CDC architectures fall short. Getting fresh data out to dozens of edge nodes at scale, with consistency guarantees, partition handling, event replay, and regional failure recovery, is a hard distributed-systems problem in its own right. Harper's native cluster replication absorbs it into the database layer. The CDC stream is paid for once at ingest, the cluster converges, and egress is paid once regardless of how many regions or consumers.
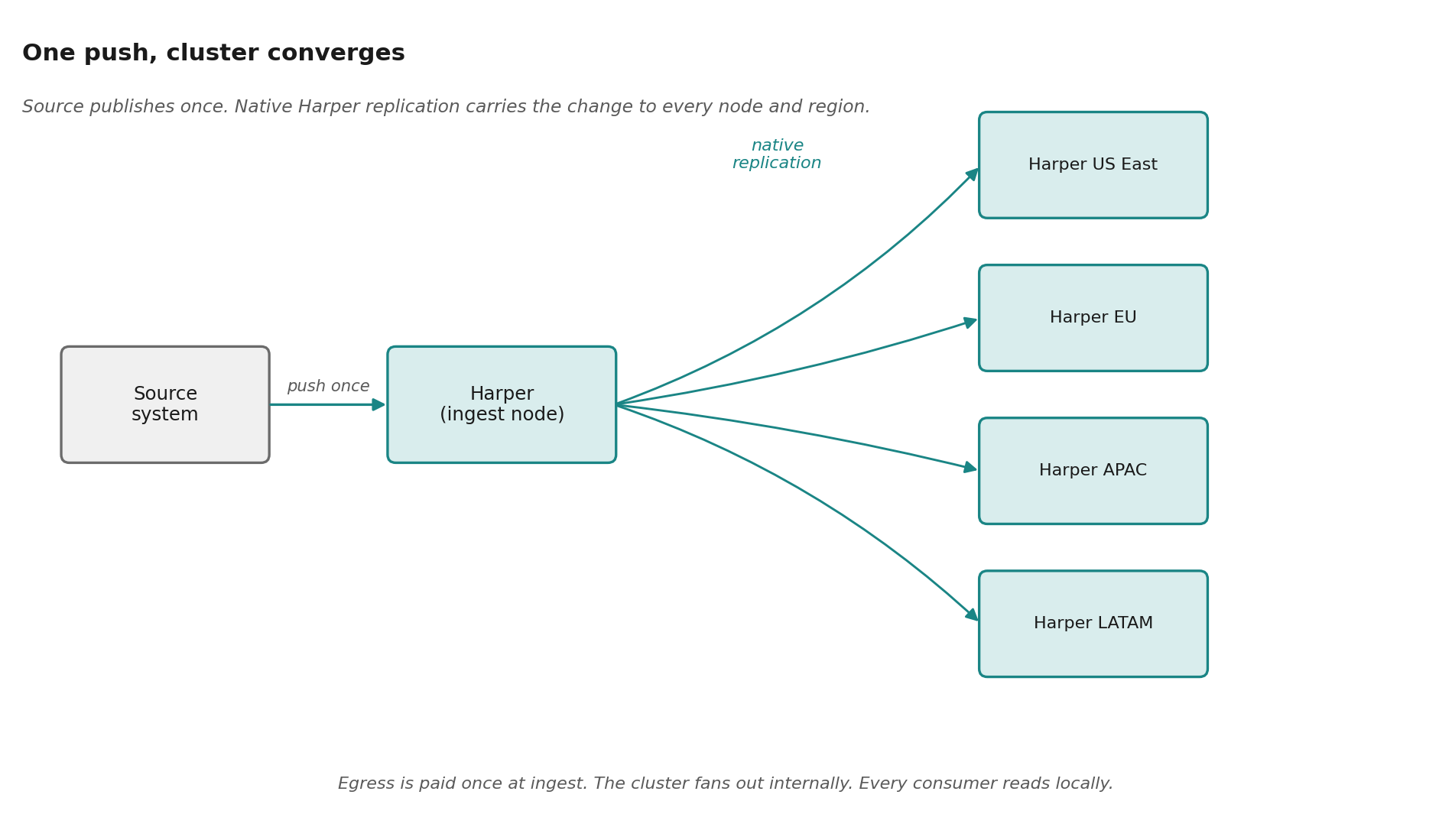
This is why Harper does not need to become the system of record to be fast. The source of truth stays where it is. Harper stays a step downstream, holding a complete, structured, queryable, replicated copy that updates the moment the source updates. The team that owns the source system does not have to migrate anything. They just have to publish their changes through the CDC pipeline they likely already have.
CDC for AI agents, not just pages
The same pattern that keeps a website page content fresh keeps an AI agent's context fresh. Most agents in production today are LLM-first. They fetch data inside the loop. Each tool call is a network round trip. Each round trip is followed by another LLM call to decide what to do with the result. Three to five LLM calls per question. Ten to twenty seconds of latency. Full token spend on context every time.
Context-first agents assemble the data before the first LLM call. Customer record, order history, inventory, business rules, and a semantic cache of past resolved questions, all queried in parallel, all in the same process as the agent loop. If the question matches a cached answer, the agent returns it without calling the LLM. Sub-50ms context assembly. Up to 85% fewer LLM calls.
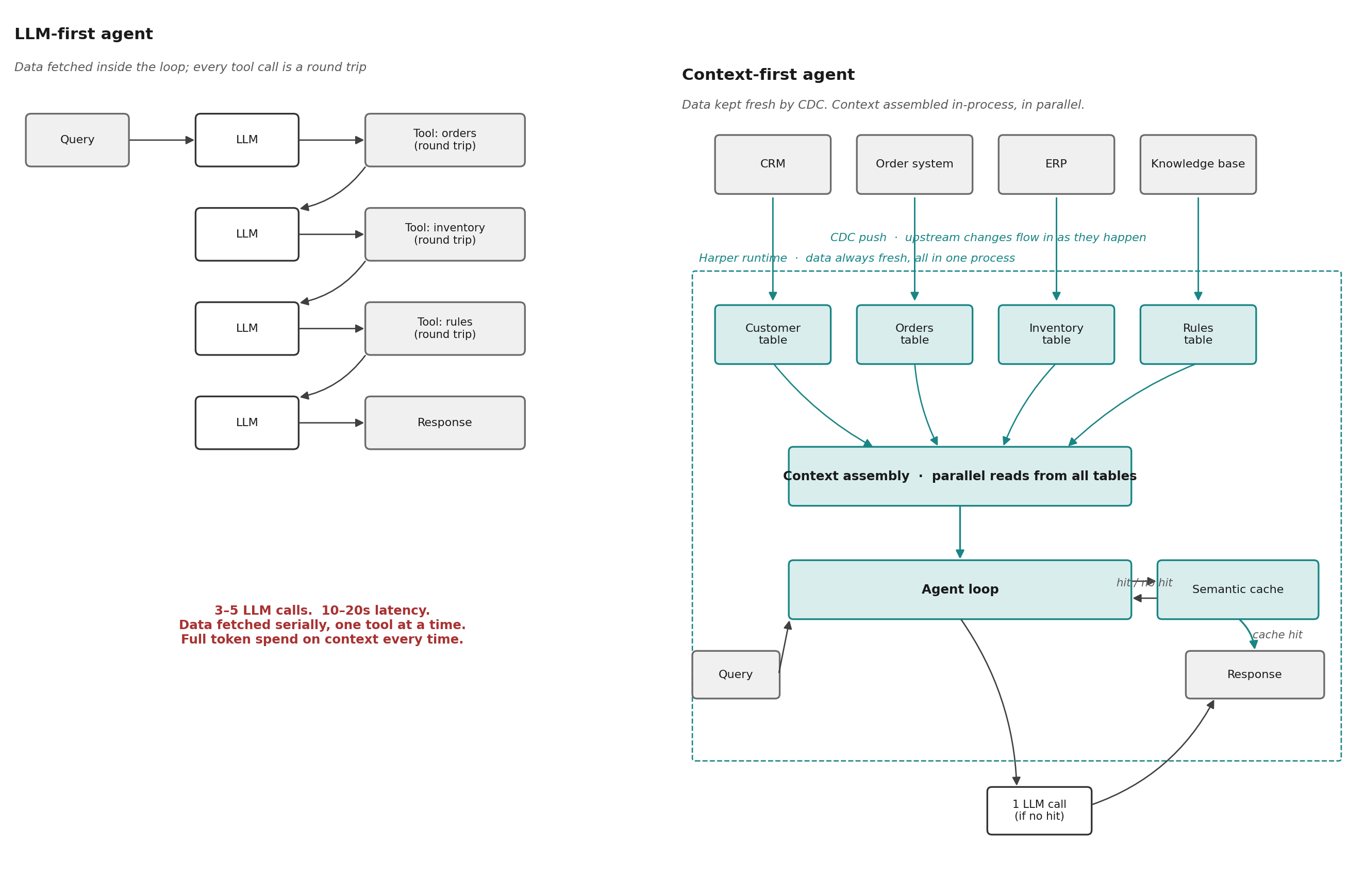
Context-first only works when the data is local to the agent. CDC into Harper is how it gets local. The same stream that pushes price changes into the Product table pushes order updates into the Order table and customer updates into the Customer table. The semantic cache is itself another CDC consumer: every resolved question is vectorized and written back, so the next similar question finds an answer without touching the LLM.
The data is fresh for the same reason it is fresh for the site content. The CDC stream landed it. The agent reads from a local table that was updated by the same change event that updated the page.
Where this ends up
There is one more architectural step available, and most teams that run CDC into Harper long enough start to consider it: making Harper itself the source of truth.
The move follows naturally from what is already in place. The CDC stream has put fresh data in Harper, in the same runtime as the workers, the search indexes, and the request handlers. The only thing still living upstream is the writes themselves. Moving the writes to Harper closes the loop. Writes can happen wherever the event physically occurs — a store, a fulfillment center, an edge POP — and Harper's native replication carries them to every other node. Reads stay local. The change feed becomes the replication protocol.
This is what makes an agent in Tokyo and an agent in São Paulo answer with the same accuracy as a central agent would, at local-region latency. It is also what lets a hundred-store retailer take a write at any store, on any web order, in any backroom, and converge to a single global view without funneling everything through a central ERP.
Most teams do not start here. They arrive when the upstream system has become the bottleneck rather than the constraint. It is a deliberate architectural decision, made by a team that has watched its CDC pipeline run reliably for long enough to trust the runtime with the writes too.
The argument
The systems that need fresh upstream data have multiplied to include page caches, search indexes, recommendation engines, AI agents, and semantic caches. The catalogs they read are large enough that scheduled refresh stopped working. The workflows that fire on each change are heavier than a simple upsert: pages get re-rendered, indexes get rebuilt, agent context gets reassembled. CDC is the standard answer to that combination, and AI workloads have made it urgent. A context window built from stale data is a wrong answer at low confidence, paid for in tokens.
The destination of the CDC stream is the architecture decision. A warehouse loads it for analytics but cannot serve from it. A queue forwards it to the next consumer. A CDN stores URL-keyed views derived from it but cannot be queried as a database. A runtime holds the data, runs the workflow on it, and serves the result directly.
Harper is that runtime. The same tables hold the cached HTML, the live product data, the agent's working memory, and the semantic cache that lets the agent skip redundant LLM calls. The CDC stream lands once, and every consumer reads from the same fresh source. The source itself can eventually move into the same runtime if the team chooses to put it there.

.webp)


.jpg)




