




How I built a desktop game that keeps its entire backend in a single Harper component, and how the same code ships as a free, fully offline download on itch.io.
I built a cozy nature-restoration game: you set up camp in a damaged nature preserve, gather materials, craft and plant habitat, reshape the land, and animals return once the habitat can actually support them. Six biomes, 150 animals, a real food web. This post is about how the backend is built, because the whole thing is one Harper component, and the database is the source of truth for the entire game.
The stack
The front end is split in two. A React and Vite shell handles the menus: title screen, character creation, crafting, the field journal. Phaser 3 handles the world itself: the tilemap, the player, animals, placing and picking up objects. Everything is TypeScript.
The back end is Harper. It is the database, the API, the content seeder, and the web host, all in one component and one process.
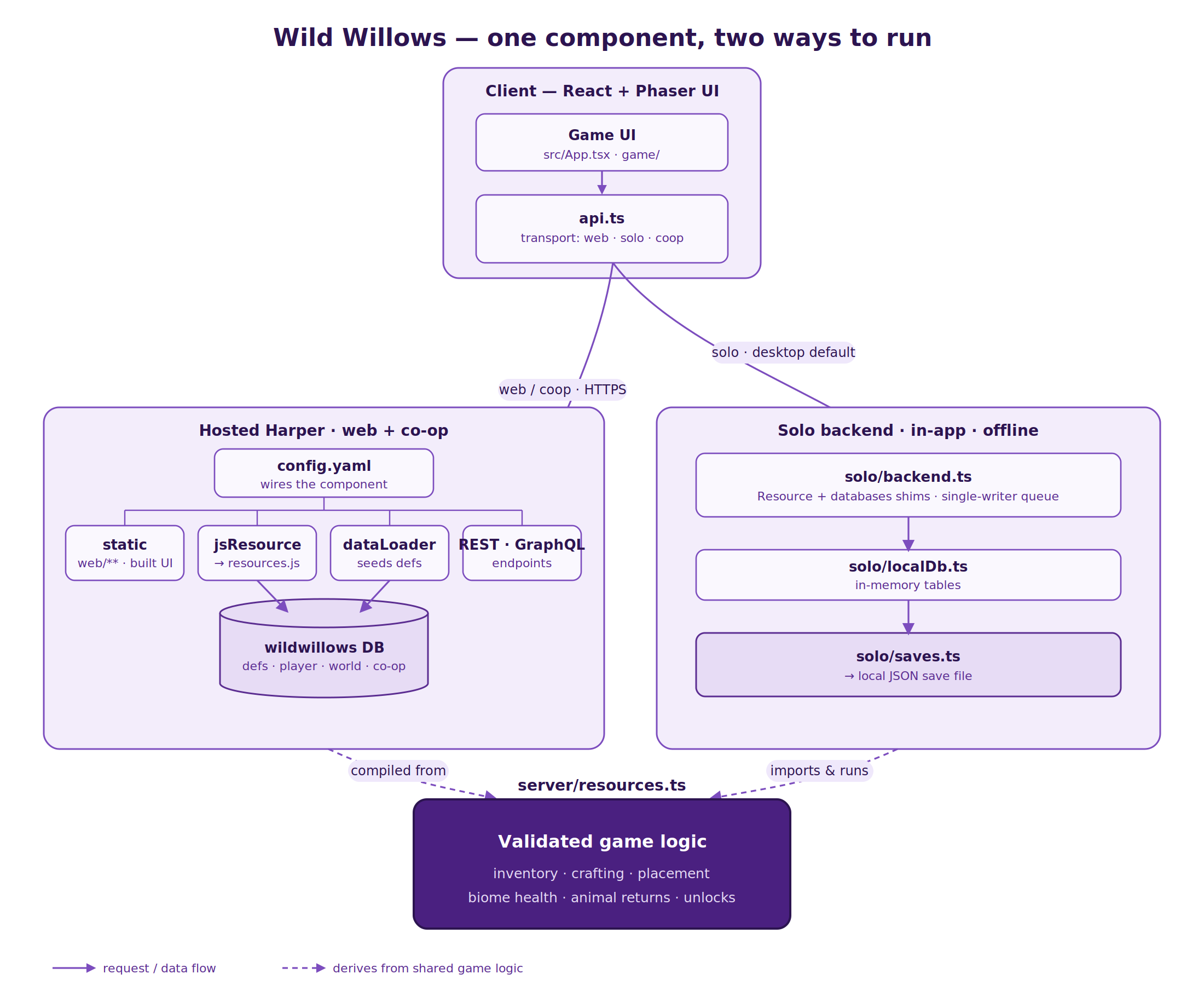
Everything in one component
A Harper component is configured by a short YAML file. This is the entire backend wiring:
# config.yaml
rest: true
graphqlSchema:
files: 'schema.graphql' # the database tables
jsResource:
files: 'resources.js' # the API / game logic
dataLoader:
files: 'data/*.json' # static game content, seeded on deploy
static:
files: 'web/**' # serves the built front end
index: true
Four declarations. graphqlSchema defines the tables, jsResource loads the API, dataLoader seeds the static content (biomes, animals, recipes) from JSON, and static serves the web build. There is no separate database to provision, no API framework, and no second host for the front end. Because the endpoint code and the data it reads run in the same process, a gameplay action reads and writes records with no network hop between the API and the database.
The schema has two kinds of tables. Definition tables (Biome, Animal, Recipe, and so on) hold fixed, typed content and are safe to index. Mutable tables (Player, Placement, BiomeState, Chest) declare only a primary key, so every other field is dynamic. That keeps them flexible while the shape of a save changes constantly during development, without breaking how existing records decode.
The database runs the game
Every game action goes through a Harper resource, which is just a class with a method per HTTP verb. None of the tables are exposed directly, because the client is never trusted. Inventory math, crafting costs, placement rules, biome health, and which animals return are all computed server side.
/** GET /GameData/ : all static definitions (biomes, animals, recipes, etc.) */
export class GameData extends Resource {
async get() {
const d = await defs();
return { biomes: d.biomes, animals: d.animals, recipes: d.recipes /* ... */ };
}
}
Mutations follow the same shape. CollectResource checks a node's cooldown and your basket capacity before granting yield. CraftItem draws materials from your basket and chests atomically. PlaceObject writes the placement and then recalculates the whole biome.
That recalculation is where the design pays off. Placing an object changes a biome's health and its ecological balance, and each animal has real return requirements: a minimum health, sometimes specific habitat or shaped water, sometimes other animals already present, since predators depend on prey. The client places an object and asks the server what happened; the server does the math and reports which animals returned and which recipes unlocked. Because all of this lives in one place, there is only ever one authority on the state of the world.
One set of logic, two ways to run
Because the logic is written as Harper resources, it turned out to be portable, and that is what makes the free itch.io release possible.
Running against Harper is how the game is developed and how it runs when served: the browser sends each action to Harper over HTTPS, Harper executes the resources and reads and writes the database in process, and returns the result.
The downloadable build is fully offline. The game logic only needs two things to exist: a databases object to read and write, and a Resource base class. When the game runs on Harper, Harper provides those. In the desktop build, the app provides its own small stand-ins: an in-memory store seeded from the same data/*.json files, wrapped in the same interface the code expects. The exact same resource logic then runs inside the app against that local store, with no network, and the world is saved to a plain JSON file on disk after each action. Harper is a development dependency here, not something bundled into the download.
A simple in-memory store is enough for this build because the desktop release is single player. The main reason to run a database server, many clients sharing one authoritative copy of the world, does not apply: there is one player and one world, the data is small, and durability comes from writing the save file. The moment you want a shared world, you go back to Harper, which is exactly why a co-op mode targets Harper rather than the local store.
Releasing it free on itch.io
For distribution the game ships as a desktop app, which wraps the web build in Electron. Electron loads the same built front end straight off disk instead of from a server, so the download opens instantly with nothing to install and no account to create. This works because the front end is built with relative asset paths, so the identical build runs both when Harper serves it at a URL and when Electron loads it from a local file. There is one build, not two, and the offline app carries its own copy of the game logic and seed data.
Each platform has to be built on its own OS, so this runs in GitHub Actions, triggered by a version-tag push. A build matrix over Windows, macOS, and Linux runners runs electron-builder to produce each platform's installer/archive, with the version taken from the tag (v0.1.1 → 0.1.1) instead of package.json. A publish job then downloads those artifacts, installs butler (itch's CLI), and runs butler push once per platform into channels named windows, osx, and linux — itch reads the platform from the channel name. It needs one secret, BUTLER_API_KEY, and only publishes on a tag, so a manual run just builds the artifacts without shipping.
The itch page itself is a one-time setup: create the project as a downloadable game, add screenshots, a cover image, tags, and the AI disclosure, and set it public. After that, every release is just a new tag. Because the app is offline and free, there is nothing else to wire up: no servers to pay for and no store backend to maintain.
How Claude and the Harper MCP scaffolded it
Much of why this came together fast is that I built it with Claude as a pair programmer, and Harper has a documentation MCP server, so Claude could read the current, authoritative Harper docs instead of guessing from memory. With the real component model, config.yaml keys, schema conventions, and Resource patterns in context, scaffolding the whole component went quickly: the initial schema.graphql, the resource stubs, the config, and the seed JSON came out using actual Harper APIs rather than plausible-looking guesses, and Harper-specific gotchas had grounded answers. It helps that Harper's core is open source: the runtime and docs are fully inspectable, with no closed layer where the real behavior differs from what is published, which is a big part of why AI assistance on it lands accurately rather than confidently wrong. Getting from an idea to a correct first version was fast, especially across Harper's specifics, so a project that could easily have taken months came together in a couple of weeks.
The takeaway
A real sandbox game, with a live food web and server-validated rules, runs on one Harper component that is at once the database, the API, the content seeder, and the web host. There is no separate database to provision, no API service to deploy alongside it, and no third thing serving the front end. For a solo developer that is the difference between shipping and not shipping, because most of the work that usually sits between an idea and a running game can feel simply unattainable.
Keeping the database as the single source of truth is what made the rest fall into place. Every rule lives in one place and runs in one process, so the client never has to be trusted and the world can never be in two states at once. That same decision is what made the code portable: because the logic only depends on a small data interface, it runs unchanged against Harper when served online and against a local store when packaged as an offline download. The hosted game and the free desktop game are the same code with different storage underneath.
The idea generalizes well past games. Any app where the rules belong with the data, and where you would rather ship one component than stitch a database, an API, and a host together, fits this shape. A game just makes the payoff easy to see: a live, server-validated world that one person can build, run online, and hand out as an offline download, all from the same Harper component.

.webp)


.jpg)



