THE WHOLE STORY, IN ONE READ
It comes down to one network hop that isn’t there.
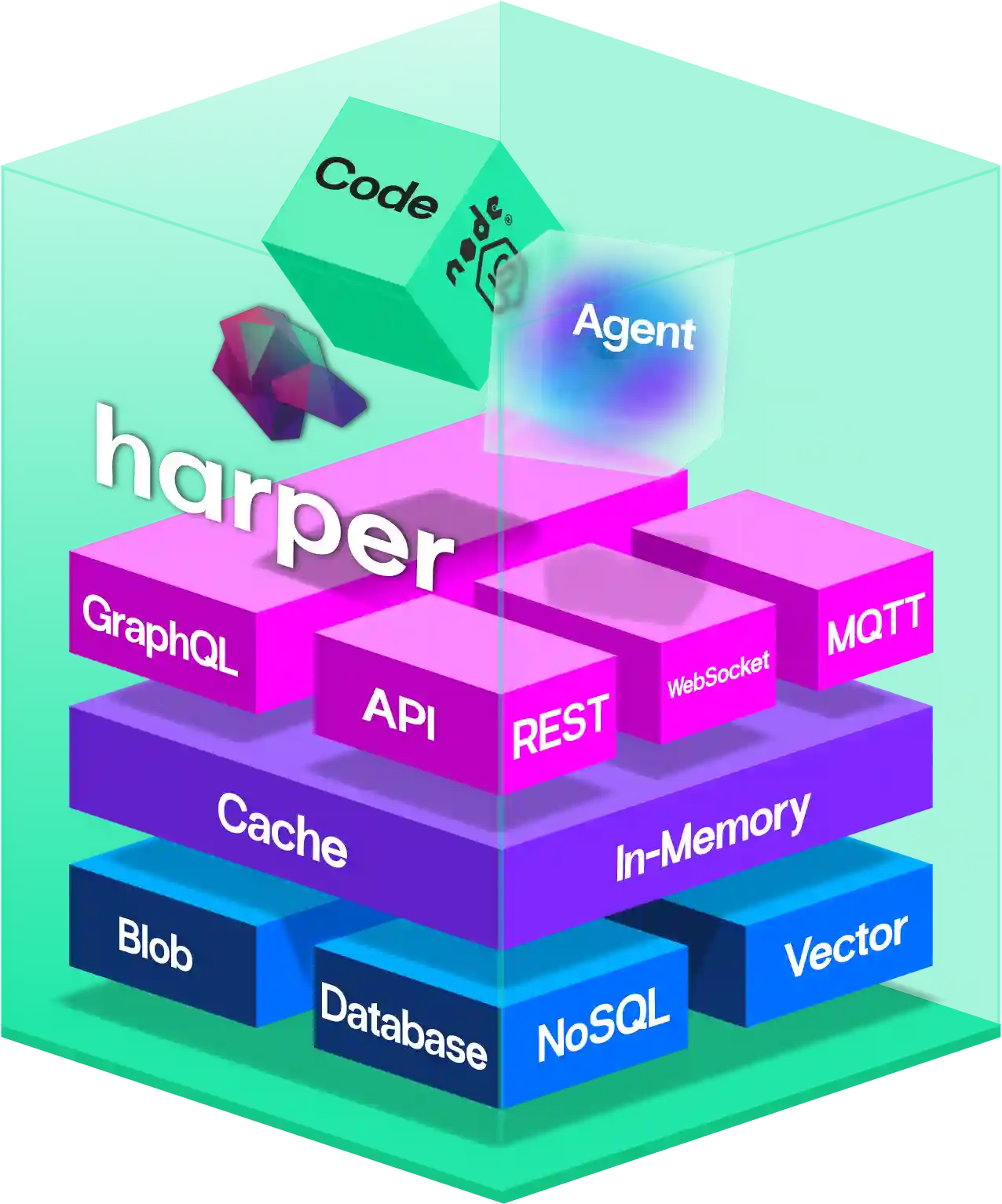
A personalized read cannot be cached at the edge, so something has to go fetch it. On the Vercel stack, the function leaves and crosses the network to Upstash to get the data. On Harper, the app runs inside the database, so the same read is a function call in the same memory. No hop. Here is one personalized read, measured on both.
same process · no hop
User
Harper
The data lives inside the app, so the read happens in memory. Basically instant. Time to First Byte was as low as 11 ms.
The data lives in a separate service, so the read has to leave the app and wait on the network. Time to First Byte was as low as 34 ms.
This is one live, personalized read at the median, about 8.5x faster on Harper. That 0.35 vs 2.98 ms gap drives every live-data result below.