




Building agents efficiently is mostly about two things: how many times you call the LLM, and what you send each time it gets called. Teams that figure this out early ship agents that pencil out in production. Teams that figure it out late get the token bill before they get the lesson.
This post walks through five architectural patterns that move both variables in the right direction, with a note on prompt caching along the way.
The Baseline
Many agents run one LLM call per decision, serially. The model says "call lookup_customer." Your code runs it. The model says "now call get_orders." Your code runs it. And so on. Each step re-sends the full growing history plus the system prompt plus the tool definitions.
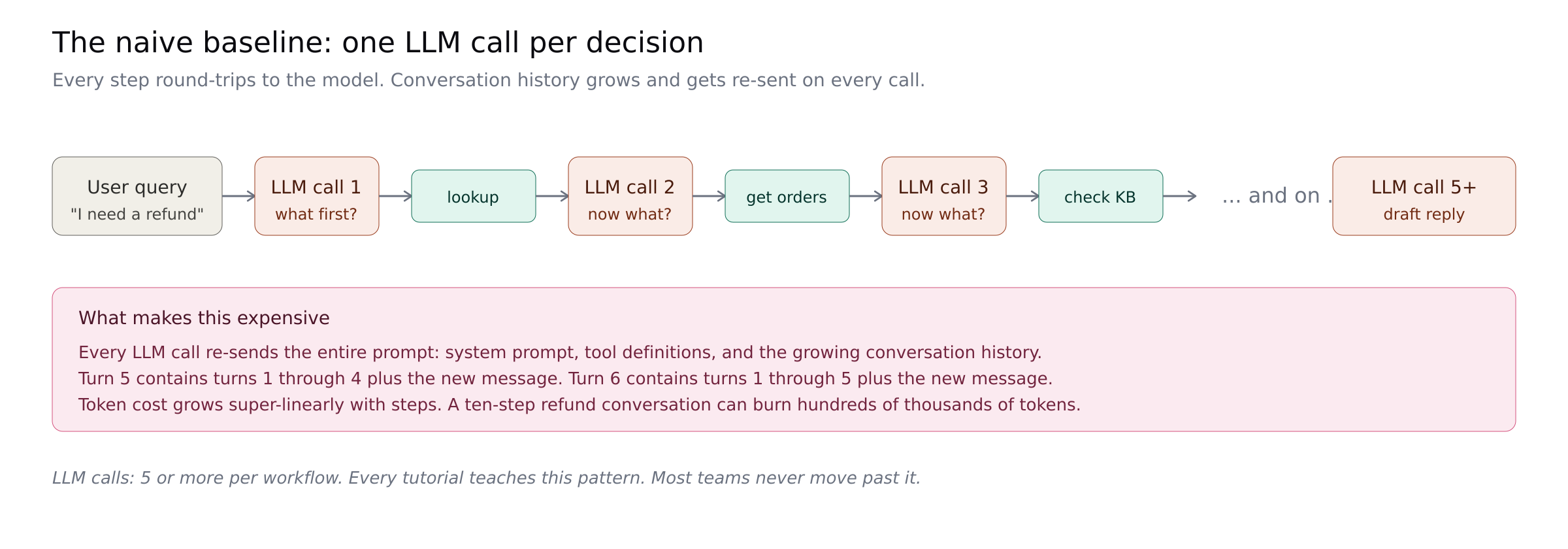
Oracle's developer blog cites a 4x token multiplier for agents over chat, up to 15x for multi-agent systems. A ten-step conversation can burn hundreds of thousands of tokens. Every pattern below is a cut into that curve.
Before the architectural patterns, one quick cost lever worth knowing about. Anthropic's prompt caching lets you mark the static parts of your prompt (system instructions, tool definitions, prior conversation history) as cacheable. Subsequent calls within a 5-minute window read those portions at 10% of standard input price. On a long system prompt or a long conversation, this is up to 90% cost reduction on the repeated content, with one config field to enable it. It does not change your architecture. It just stops you paying full price for content you already sent. As of early 2026, Anthropic supports automatic caching where the cache point moves forward as the conversation grows. Turn this on for the baseline pattern and every pattern below. It stacks with everything else in this post.
Moving orchestration out of the LLM
The first three patterns share an architectural shape: the model makes one call to decide the work, code runs the tools, and the model makes one final call to compose the reply. What varies between them is who decides the sequence of tool calls and when that decision gets made. That choice has consequences for how adaptive, how auditable, and how predictable the resulting agent is.
All three cut the naive 5+ call loop down to 2 LLM calls. The right choice depends on how much of the workflow you know in advance.
Parallel tool calls
Modern models can return multiple independent tool calls in one inference. Instead of four sequential turns to gather four pieces of data, the model outputs all four tool calls in one response and your code fires them concurrently.
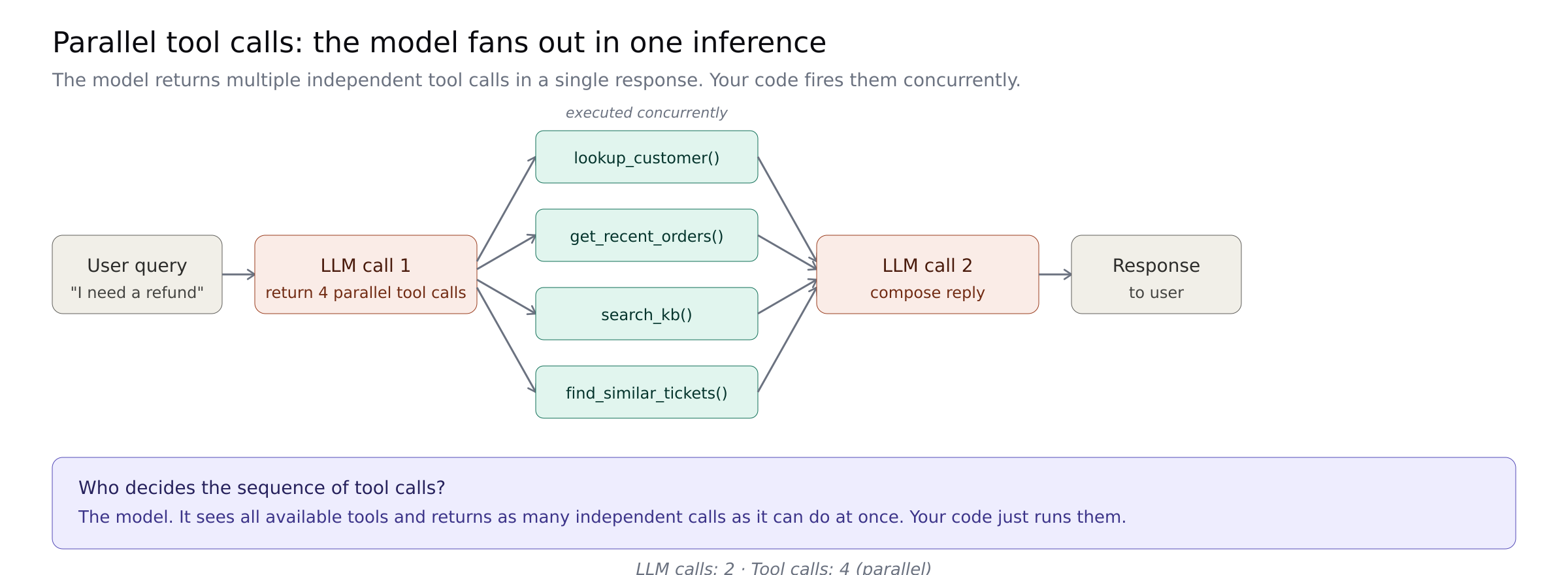
Anthropic's guidance confirms Claude 4 models do this natively. The anthropic-parallel-calling repo shows the pattern end-to-end.
Who owns the sequence: the model, at inference time. It looks at the available tools and decides what to fire in parallel.
Best for: data gathering where the pieces are independent. Lookups, searches, enrichment calls that do not depend on each other.
Where it breaks: parallel only helps if the tools are actually parallel. If each call hits a different vendor with its own rate limits, you are bottlenecked by the slowest one. The first time you notice is usually when a rate limit on one API causes the whole turn to stall while three other calls sit completed waiting for the fourth.
Plan, then execute
For dependent work, ask the model for a plan as structured output. Your code executes the plan step by step. Retrieval and validation steps do not need the LLM at all. Only steps that require reasoning go back to the model.
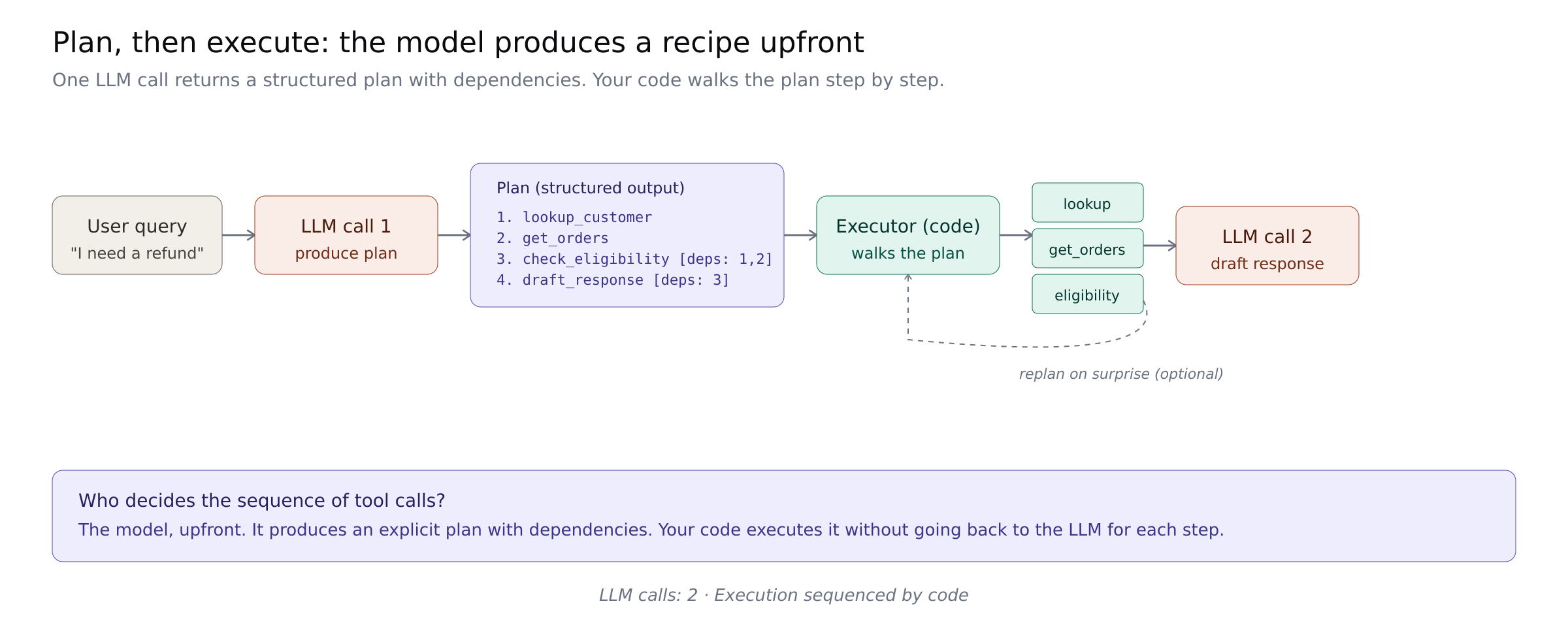
Anthropic calls this programmatic tool calling and reports that orchestrating 20+ tool calls in code "eliminates 19+ inference passes." The Anthropic Cookbook patterns repo has working implementations.
Who owns the sequence: the model, upfront. It produces an explicit plan with dependencies that your code then walks.
Best for: multi-step workflows where the steps depend on each other's outputs but the overall shape can be determined from the original request.
Where it breaks: the plan meets reality. If step three reveals something unexpected, the plan needs to be re-planned. Production implementations need a "replan on surprise" trigger or they commit wrong actions against stale assumptions.
Deterministic code paths
The most powerful pattern and the most under-discussed: do not call the LLM for decisions it does not need to make.
For a refund request, looking up the customer, getting their orders, and checking the policy are not decisions. They are the routine work any refund triggers. You do not need the LLM to tell you to do them. Detect the intent, then run the sequence in code. Call the LLM only for language understanding (classifying the intent) and reasoning (drafting the response).
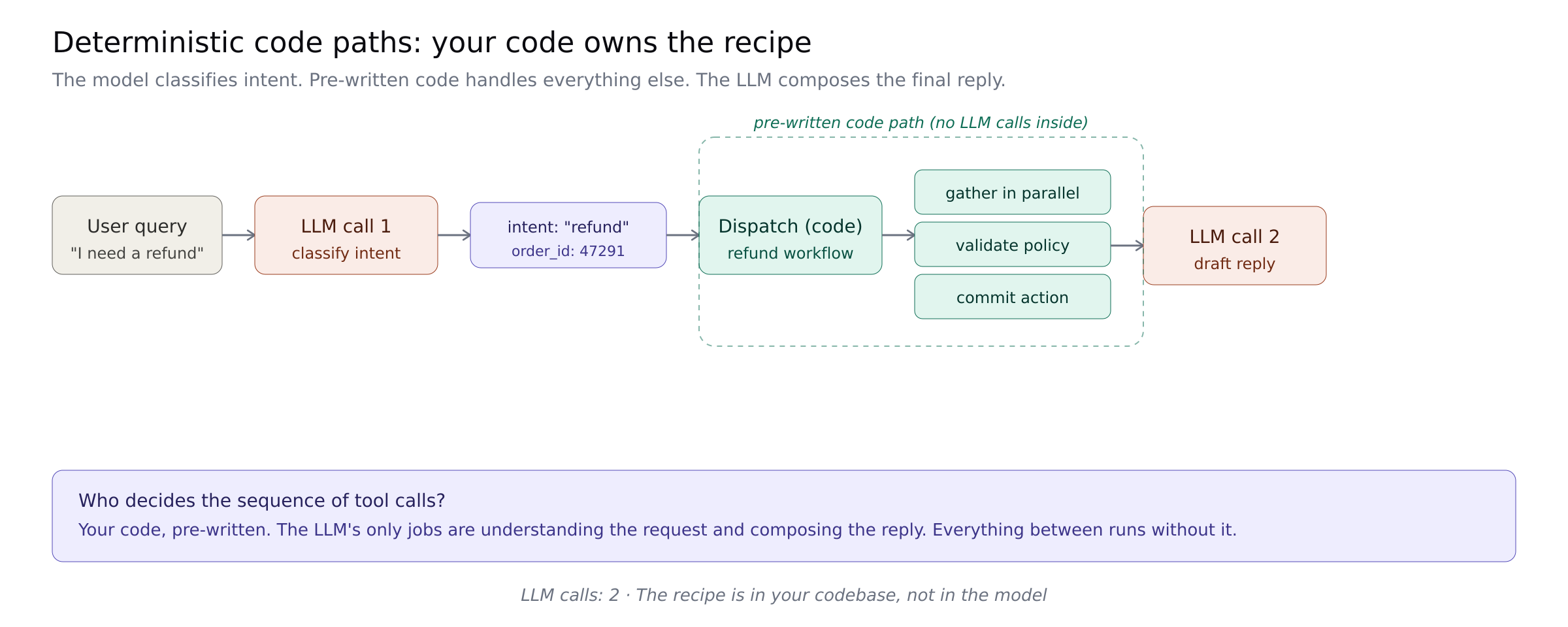
A conversation that could have been 8-12 model calls becomes 2-3. This is how Stripe and Shopify build their AI features: "The orchestration layer is deterministic; the AI operates within it." The n8n team has templates you can run today.
Who owns the sequence: your code, pre-written. The workflow shape lives in your codebase, not in the model.
Best for: well-known routine workflows where the sequence of operations is the same every time. Support categories, order processing, approval chains.
Where it breaks: your coded path meets a case you did not anticipate. The failure mode is that your agent works beautifully on 80% of cases and escalates awkwardly on the 20% you did not code for. The fix is honest scoping: name what the deterministic path handles and route everything else to an agentic fallback.
Semantic caching
The three patterns above reduce how many LLM calls you make. The next two reduce them further by skipping calls entirely when the answer has already been generated.
If a user asks something semantically similar to a past query, return the cached answer instead of regenerating it. "How do I reset my password?" and "I forgot my password" are the same intent. String caches miss. Semantic caches hit.
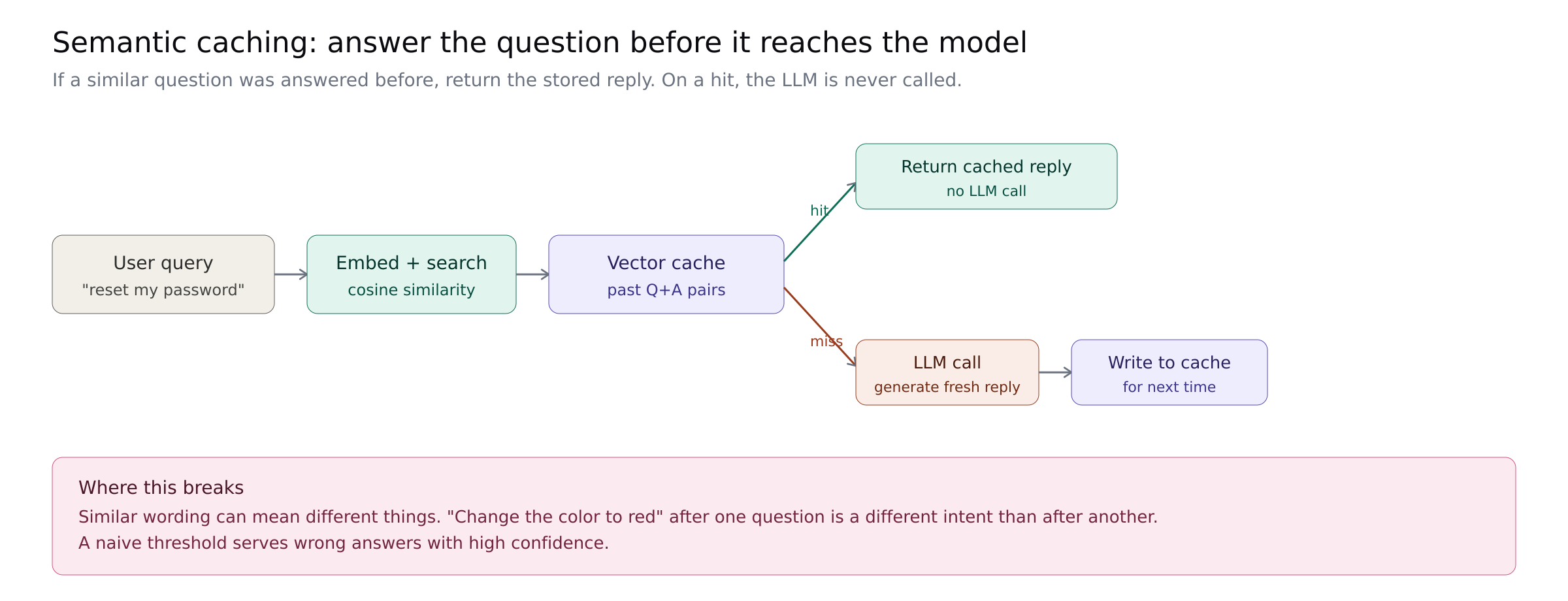
GPTCache is the canonical open source implementation. The GPT Semantic Cache paper measured 61-69% hit rates with 97%+ accuracy on hits.
Best for: workloads with repetitive user questions. Customer support, documentation lookups, FAQ-like interactions.
Where it breaks: the failure mode is worse than a cache miss. The MeanCache paper documents cases where GPTCache returned incorrect cached responses for contextually different queries that scored high on semantic similarity. A naive threshold serves wrong answers with high confidence. Production implementations need context-aware matching, threshold tuning, and validation on returned answers.
Pattern caching
Almost nobody is shipping this yet. It might be the biggest unclaimed cost-saving pattern in agent infrastructure.
Semantic caching assumes that similar questions share answers. That breaks the moment the question is about different specifics. "Can I refund order 47291?" and "Can I refund order 83104?" are semantically nearly identical and absolutely should not share a response.
But the question cannot reuse the answer, but it can reuse the workflow. Both queries trigger the same sequence of tool calls, the same validation steps, the same response shape. The specifics differ. The plan does not.
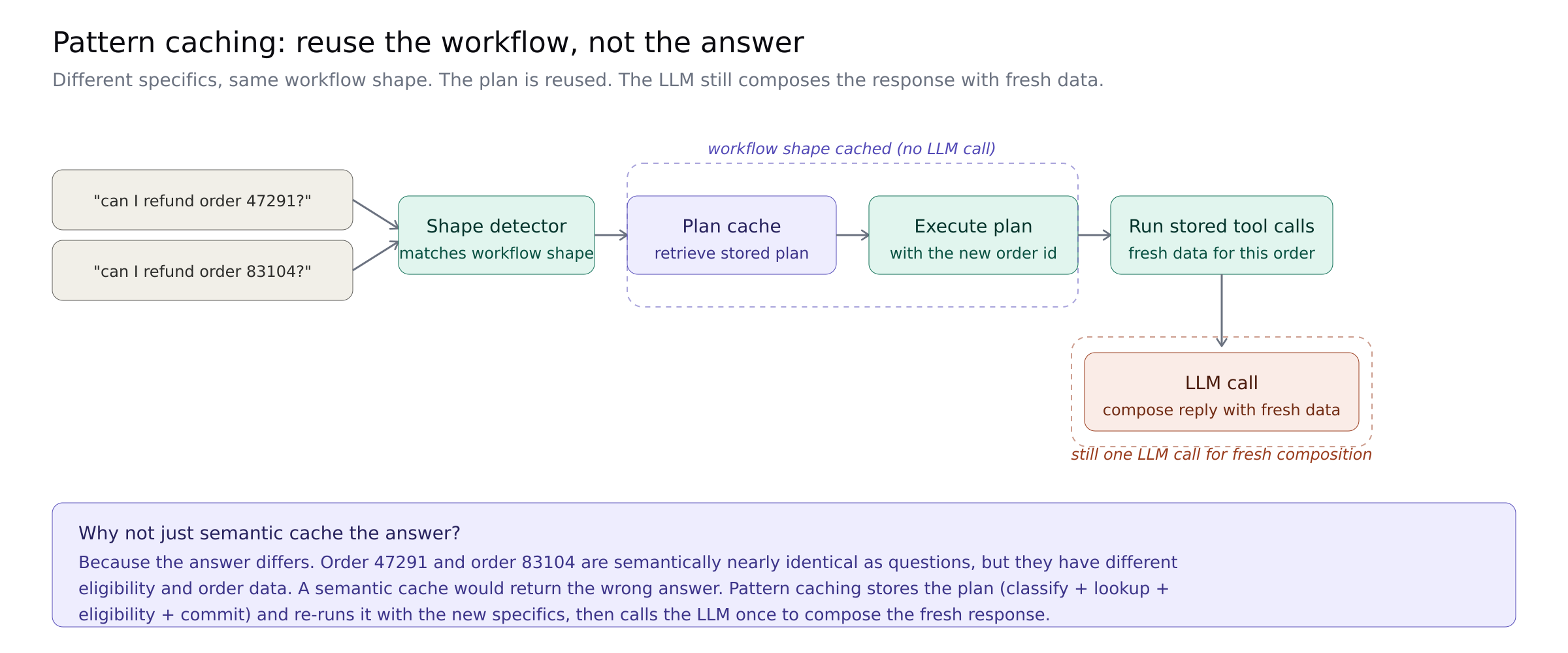
A pattern cache stores the execution plan rather than the response. New query comes in, the system recognizes the shape, retrieves the stored plan, executes it with the new parameters, and calls the LLM once to compose the response with fresh data.
The economics shift significantly. Instead of every refund query triggering a full agentic planning loop, the first refund query produces a plan and the next ten thousand execute that plan with new parameters, with a single LLM call for composition.
No first-class implementation exists yet. GPTCache generalizes toward responses. LangGraph expects you to define graphs by hand. The pattern caching that exists in the wild is ad hoc: teams hand-code the dispatch path for their common workflows (that is the deterministic paths pattern above) and the cache is their codebase.
The team that ships this as a runtime primitive, where the system learns which workflows repeat and caches their execution plans automatically, sets the terms for what agent infrastructure means in 2027.
Where it breaks: the risk of a pattern cache is the same as the risk of any cache, amplified by the fact that workflows have side effects. Serving a stale response is embarrassing. Serving a stale plan that commits a wrong action is a rollback. Pattern caches need stronger invalidation logic than response caches, because the inputs to the plan can change in ways that invalidate the plan itself (a policy changes, a tool is deprecated, an upstream API signature shifts). Getting this right is the reason it has not shipped yet.
What this costs on a distributed stack
Every pattern here works on any runtime. None of them are Harper-exclusive. What differs is how expensive they are to implement together.
Parallel tool calls help most when the tools are fast and local. Deterministic code paths work best when the code lives alongside the data it touches. Semantic and pattern caches need a vector index next to the embedding generator, both updated continuously as the agent runs. Prompt caching is provider-side, but the agent orchestration that makes caching effective lives in your runtime.
On a distributed stack (LangChain + Pinecone + Redis + Lambda + a memory service + an observability vendor), implementing all six patterns means coordinating across five or six vendors. The patterns still work. The operational overhead of doing them all well is what stops most teams at one or two.
Most teams that ship all six either have a dedicated agent infrastructure team or a runtime that makes them the default. We built Harper for teams that do not have the first. On a unified runtime where the agent, the data, the vectors, the memory, and the deterministic code all share a process, these patterns become the path of least resistance. Parallel tool calls run in-process. Deterministic steps run next to the data. Semantic caching happens against local vectors. Pattern caching becomes a runtime primitive instead of a distributed-systems problem.
The patterns are universal. The friction of implementing them is architectural. If every pattern here sounds like an engineering project you cannot find time for, that friction is not your team's fault. It is the architecture telling you something.

.webp)




.jpg)
