




Have you heard the term “edge persistence” floating around the webiverse? If so what does it mean to you? If your answer is “not sure” then this blog is for you! If you think you have an idea, let me know where you think I got it right and where I might have been off. Edge computing is the first aspect of this concept. Edge computing is the salt to cloud’s pepper. Blending edge computing with the cloud creates flexibility you would not be able to achieve with one or the other, with the added benefits of improved performance and reduced latency. So what do I mean when I say salt and pepper? They go great on dishes separately, but when combined can add the perfect finish to your cooking. Edge computing brings your computation and data storage closer to the location where you need it. It improves performance and reduces latency when running your application or technology. Now for the word persistence, I used a good old-fashioned dictionary. To be persistent is “existing for a long or longer than usual time or continuously.”
So edge persistence allows companies to globally distribute their applications, software, and technologies closer to the end-user location where it improves performance and reduce latency. When I say latency, what does that mean? Latency “is an expression of how much time it takes for a data packet to travel from one designated point to another”. It does so continuously for long periods of time.” I could end this blog here, but that wouldn’t be a very informative blog, so let’s go deeper.
The Not So History of Edge Persistence
So who was the first person to use this term? When did it become a term? Oh, and where? For what purpose? So many Qs. I am not going to lie, there wasn’t a lot of information to be found on this exact concept. Hence the header for this section. I found info on data persistence and ETL persistence, but even Wikipedia didn’t have a page for edge persistence yet. So instead I’ll focus on the history of edge computing, then we’ll add persistence to the end of edge and discuss how that came to be.
The need for edge computing was born in the early 1990s as demand for faster video and image downloads along with web pages themselves started to explode. Enter Akamai, you may have heard of them, a company that decided to create content delivery networks. This was a driving factor in the birth of what we know to be edge computing. What is a content delivery network you might ask? Akamai has a great article explaining what it means and how it works. Here is their definition (I figure its the best since, ya know, they created them), “A CDN (Content Delivery Network) is a highly-distributed platform of servers that helps minimize delays in loading web page content by reducing the physical distance between the server and the user.“
Edge computing takes the idea of CDN one step further and generalizes it. This is because CDN was created to bring the content closer to the end-user, and as we discussed earlier, edge computing brings all the datas, apps, and tech closer to the end-user. From there in 1997, Brian Noble and his team did a study that provided insights into edge computing on mobile phones. Peer-to-peer or distributed applications later came in 2001 which made apps more scalable and decentralized. I could dive further into the different types of computing like cloud and fog that developed and their deeply intertwined histories, but instead, I attached this great graphic created by the folks at bosch.io. The article that this was originally included in goes into detail about how edge and cloud computing came to be what we know today. Oh also, I just wrote an “Explained” blog on hybrid cloud so check that out as well.
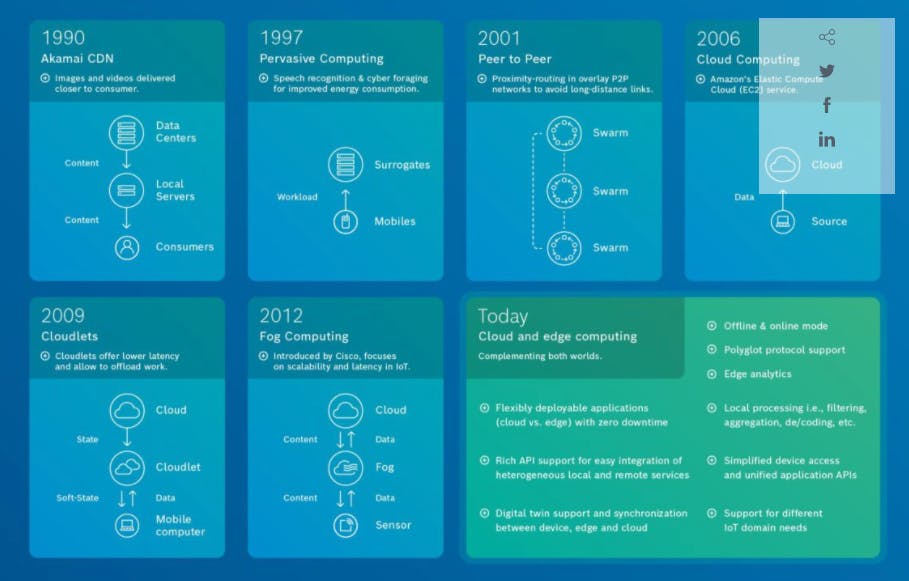
Image Source: Bosch.io
So to end our history lesson for today, knowing that we understand where edge computing came from, we can put the persistence on the end and learn why we put these two things together. The need for faster applications, faster data analysis, faster content delivery, and more scalability has pushed companies to find ways to decrease application latency. This need to have hyper-fast apps that move at the speed of the Internet has exploded in the last few years and it will only continue to grow. So persistence on the edge, to me, comes more heavily into play in the late 2010s when we start to see the rise of IoT, artificial intelligence, machine learning, and the evolution of the “smart” everything in our lives. We not only need reduced latency but we need it all the time. That means all day and all night. Gone are the days when we logged onto our computers for a couple of hours or only used computers for work. So voilà, we need persistent edge computing in 2021, longer uptimes, and lower latency baby.
Who Needs Edge Persistence Anyways?
Let’s first talk about industries that need to have globally distributed edge persistence when running their tech or application. First off, I want to direct you to an excellent resource that discusses specifically industries that need a high-performing low latency database by my colleague, Margo McCabe. Here are some of the industries that really need to focus on implementing edge persistence into their products and solutions:
1.Gaming & Media- Have you ever been playing a video game and notice a small lag? You might be playing someone halfway across the globe. Did you know that there’s a big chance that even though you are here and they are in say Hong Kong that data for both of you is flowing to a single, centralized data center for the globe (possibly not near either user). Why doesn’t your data flow through a data center here and their’s in a data center there? Edge persistence can fix this through globally distributing the database used by your favorite gaming company at data centers closer to the end-user.
2. Military & Industrial- There are massive amounts of data flowing through warehouses, production lines, and delivery trucks, sometimes on a global level. Situational awareness can be driven by sensor data collection in the field, and the location can be global. If mission-critical data isn’t getting to where it needs to be on time, expensive and dangerous mistakes can follow.
3. Energy (Utilities, Oil & Gas, Mining)- When working in energy, people rely on these companies to keep the lights on while also protecting workers and those living around work sites. Data plays an important role in planning ahead. Latency can cause catastrophic mistakes that affect millions of people. The ability to make rapid decisions and execute on them in real-time is crucial.
4. Retail- Online shopping dominates the retail space and customers are demanding. A poor user experience is as simple as a user having to wait more than a second for a company’s web page to load while shopping. It’s as simple as that to turn away a large number of customers.
Why Global Edge Persistence Will Change the World
We know where the need for edge persistence has come from, and we know the history and evolution of edge computing into edge persistence. We also have some ideas of what industries and use cases would benefit from edge persistence. When I say edge persistence will change the world, I know some of you had to roll your eyes. That is a huge claim to make so let me explain. We take for granted the speed of the Internet, and the software and apps that load in milliseconds at our fingertips. The world is constantly moving at a faster pace and so will every application or software that we use. As data becomes more intricate to how we live, work, and how the world keeps moving forward, we will need these insights and decisions at faster speeds. There are also use cases as we covered above that cannot afford to have lagging speeds, downtimes, and poor performance as the consequences could be great.
With edge persistence, gone will be the days of having to skip the movie on your favorite streaming app because the show won’t load. Retail sites will load each page in less than a blink of an eye as you browse for your favorite sneakers. Production lines will be able to make smarter, faster, and more informed decisions, cutting back costs and getting products you love out even faster. Edge persistence is the future and we will start to see this term pop up a lot more frequently. We might even see a Wikipedia page for it before the year’s end. I chose to dive into edge persistence this week because here at Harper, we are at the forefront of edge persistence technology. We enable companies to create a unified data fabric across the globe with Harper distributed across a multitude of data centers, independent of the provider. A cloud independent database provides the opportunity to choose the right data center location anywhere, instead of deciding between limited centralized locations. Again, would love to hear you’re feedback on this blog, and if you have any other good resources on edge persistence send them my way!






.jpg)
