




What is a database cluster?
Database clustering is the process of connecting more than one single database instance or server to your system. In most common database clusters, multiple database instances are usually managed by a single database server called the master. In the systems design world, implementing such a design may be necessary especially in large systems (web or mobile applications), as a single database server would not be capable of handling all of the customers’ requests. To fix this issue, the utilization of multiple database servers that work in parallel will be introduced to the system.
It goes without saying that using such a technique comes with numerous benefits to our system such as handling more users and overcoming system failures. One of the main disadvantages of such implementation is the additional complexity introduced into the system. To handle additional complexity, multiple database servers should be managed by a higher-level server that monitors the flow of data throughout the system.
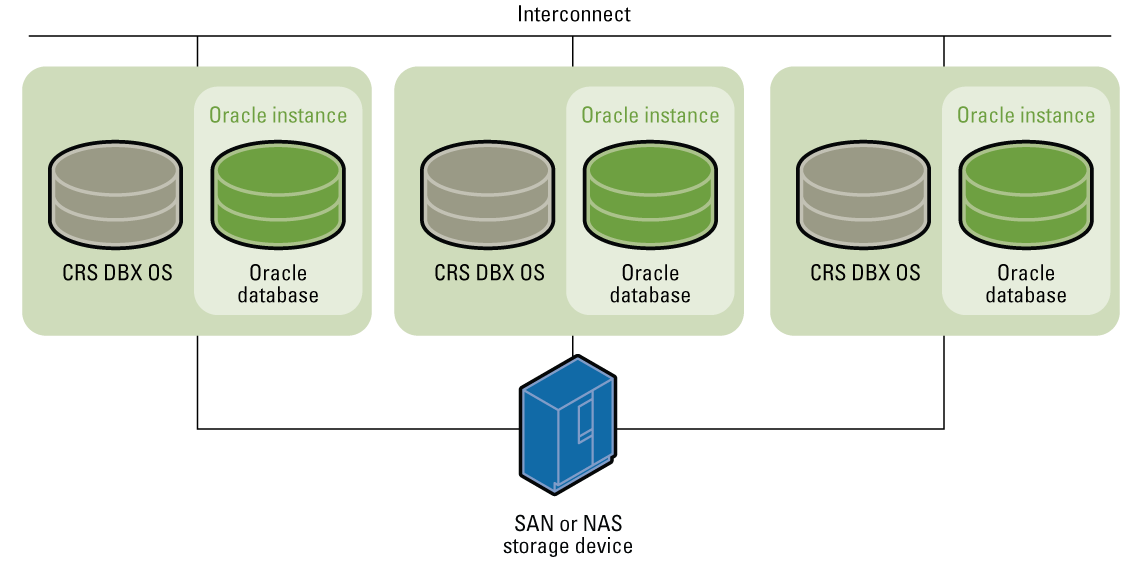
As shown in the above image, multiple database servers are connected together using a SAN device. SAN short for Storage area network is a computer network device that provides access to consolidated, block-level data storage. SANs are primarily used to access data storage devices, such as disk arrays and tape libraries from servers so that the devices appear to the operating system as direct-attached storage. While you still can build your own database cluster, recently, companies do provide third-party cloud database storage as a service for customers. Using such services customers can save costs on maintaining and monitoring their own database servers or clusters.
In this article, we will explain the two most common clustering architectural types. Moving on we will provide you with some advantages of database clustering.
Database Cluster Architecture
Shared-Nothing Architecture
To build a shared-nothing database architecture each database server must be independent of all other nodes. Meaning that each node has its own database server to store and access data from. In this type of architecture, no single database server is master. Meaning that there is no one central database node that monitors and controls the access of data in the system. Note that a shared-nothing architecture offers great horizontal scalability as no resources are being shared between either nodes or database servers.
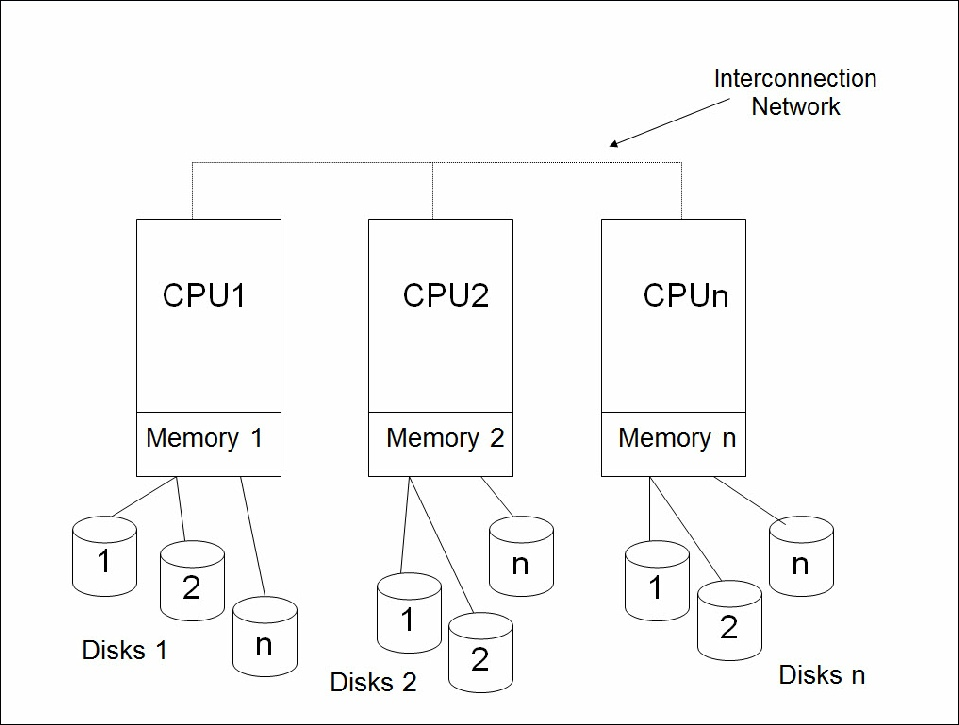
An image of a shared-nothing architecture (Source)
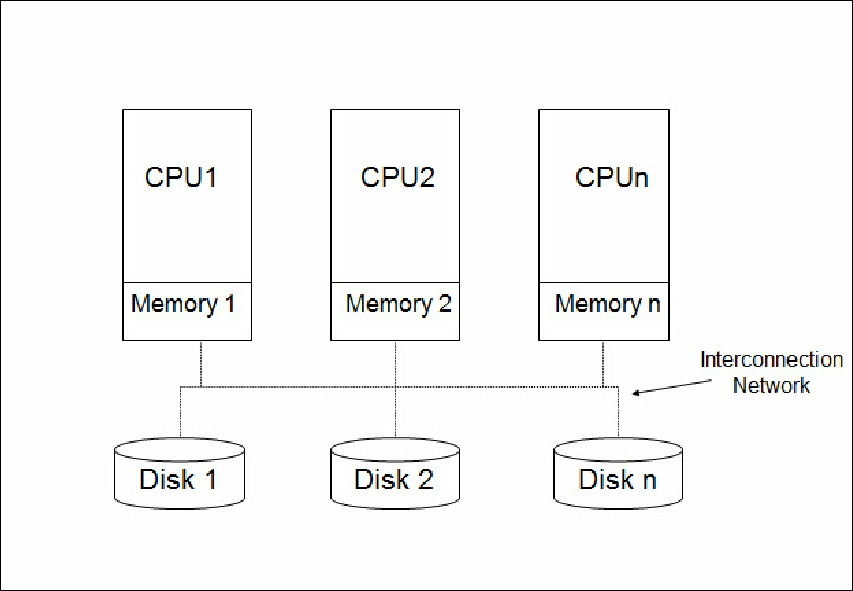
Shared-Disk Architecture
On the other hand, we have the shared-disk architecture. In this architecture, all nodes(CPU) share access to all the database servers available, subsequently having access to all the system’s data. Unlike the shared-nothing architecture, the interconnection network layer is between the CPU and the database servers allowing for multiple database servers' access. It is worth noting that a shared disk cluster does not offer much scalability when compared to the shared-nothing architecture, as if all nodes share access to the same data a controlling node is required to monitor the data flow in the system. The issue is that after exceeding a certain number of slave nodes, the master node would be unable to monitor and control all the slave nodes efficiently.
Advantages of database clustering
- Load balancing the system
Load balancing is the process of distributing a given number of tasks onto multiple different resources. The aim of such a task is to make the overall processing of the system much more efficient. The main reason for performing load balancing is to prevent the chance of any system overload causing a sudden system failure.
While a small application might not require multiple databases, as an application grows, the need for introducing more servers will be required. While it is still applicable for companies to replace their database server with more efficient ones, there is a limit to how many requests that a single server can handle. To solve this issue, multiple database servers are introduced into the system. Along with a master node that will distribute the user requests among them equally. The idea is to not overload a single server while keeping other servers free.
- Reaching more customers
One of the main reasons why companies invest in database clustering is scalability. By adding more database servers, companies can handle a much greater number of users from different parts of the world.
Note that having multiple database servers implemented in different geographical locations will allow for faster customer interaction by having the actual database server closer to the customer's geographical location. This will be necessary for worldwide used applications such as Facebook, Youtube, and Google with users all over the world..
- Data redundancy across the system
Data redundancy is the process of storing data in two or more different storage spaces. In the case of database clustering, while they may be multiple database servers, all servers must hold the same exact data. Data redundancy is so significant because if one database server gets corrupted (data is lost or changed) we can still have a copy of the data stored in another database server. In cases where an issue occurs in a given system’s database, data redundancy can be the
- Overcoming the risk of application failure
By having multiple database servers working in parallel, database engineers can overcome the single point of failure issue. If an application has only one database server and this server fails or goes down then the system can be considered halted. To resolve such issues, other database servers must be on standby. You may never know when a database server is going to go down, thus it’s always better to keep other servers available. Note that the difference between data redundancy and application failure is that in the case of data redundancy all data is lost. On the other hand, in the case of a single point of failure, the database server is down for a limited amount of time and is expected to be up and running again, thus the system can still function but it has no space to store or retrieve data in the current time.
Clustering with Harper
Harper allows for database clustering by having the Harper clustering engine replicate data between multiple instances of the database. This approach follows a high-performant, bi-directional pub/sub model on a per-table basis. As with most database clustering solutions, Harper offers load balancing, data redundancy, and high data availability.
Using Harper, data is replicated asynchronously across all the database servers in the cluster. Individual transactions are sent in the order in which they were transacted and are processed in an ACID-complaint manner. By having an ACID complaint system, all the database transactions are guaranteed to maintain high data validity despite errors, power failures, and any other mishaps that might occur. Learn more about Harper clustering in the docs here.






.jpg)
