




Introduction
Ever since computers were first introduced, the primary emphasis has been on data processing. Within this realm, three main processing methodologies have emerged as dominant including real-time, batch, and stream processing, each with its unique applications and advantages in the ever-evolving landscape of data management.
What is Real-Time Processing?
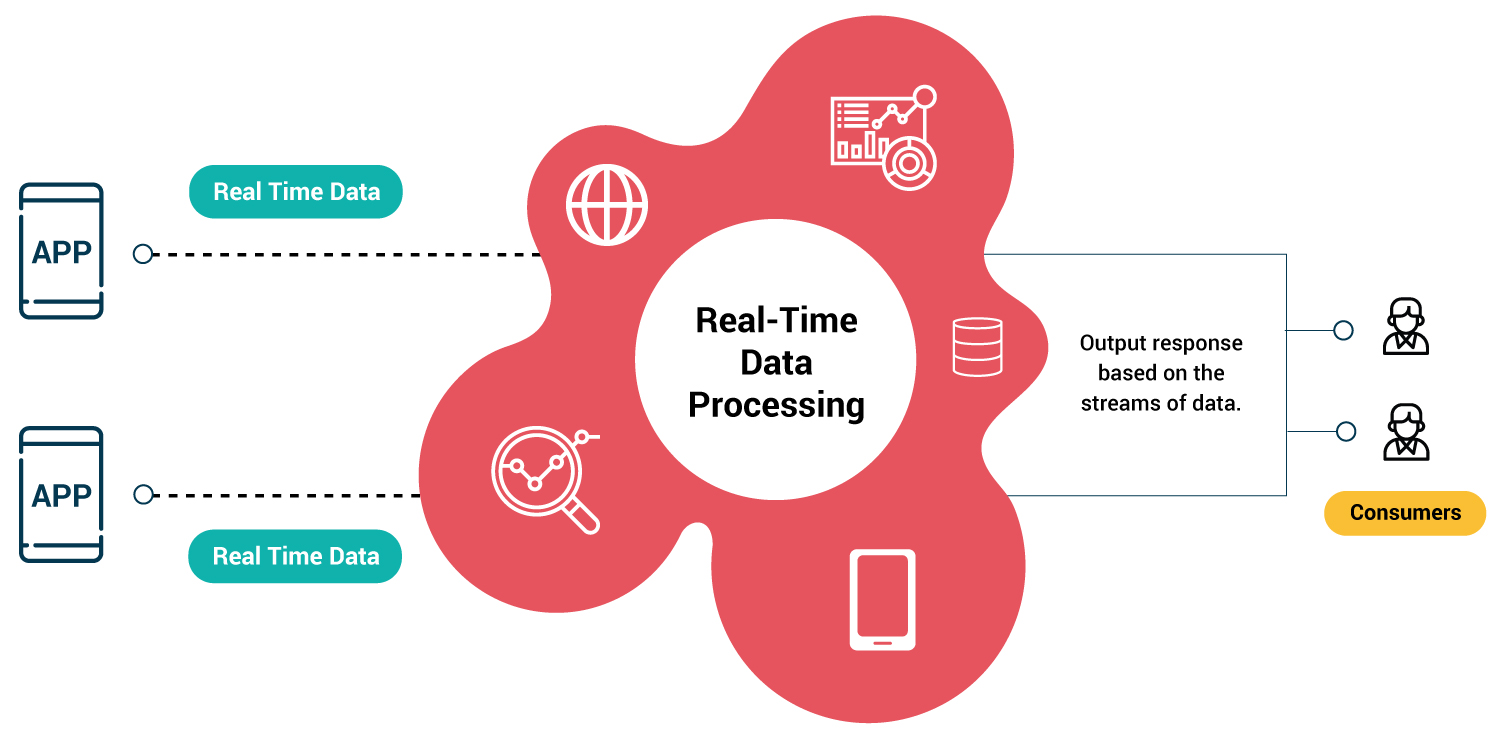
Real-time data processing is a computing method that processes data as they occur. The primary goal of such a system is the immediate response to real-life tasks.
A significant application of real-time processing is within embedded systems. These are specialized computing systems embedded within larger devices, and they play crucial roles in various industries, from automotive to medical and beyond. Within these contexts, the demands are often high for swift sensor data acquisition and prompt data processing. For example, a vehicle's braking system might rely on real-time processing to detect sudden obstacles and command an immediate brake, or a medical monitor might need to provide live feedback on a patient’s vitals, triggering alarms if any irregularities are detected.
In essence, real-time processing stands as the backbone for systems where lag or delay is not just inconvenient but potentially hazardous. Its value cannot be overstated in applications where timing is everything, ensuring that technology keeps pace with the rapidly changing environments and situations it is designed to manage.
Benefits
- Immediate Responses: Real time processing facilitates swift interactions between requests and responses, enabling quick decision-making. As we will see frequently in the below examples.
- Enhanced User Experience: In user-focused applications like online gaming and social media apps, users anticipate prompt and fast reactions, resulting in a smoother experience.
Use Cases and Applications
- Medical systems: These include complex systems such as heart rate monitors, which rely on real-time data reading and processing. The immediacy in these systems is crucial, given that they can be a matter of life and death.
- Fraud Detection: Banks and credit card companies alike, utilize real time processing in order to detect fraud attempts. Advanced systems analyze transactions in real-time, enabling these institutions to spot suspicious activities early on. By doing so, they can promptly stop fraudulent transactions before they are completed, thereby averting potential financial losses.
Challenges
- High system complexity: In applications that demand massive scalability, businesses often invest heavily in sophisticated and costly infrastructure systems to cater to instantaneous user responses.
- Complex Scheduling: Real-time systems often have to juggle multiple tasks with different priority levels and timing constraints. Crafting a scheduling strategy that can handle these tasks and meet all deadlines can be complex. Some of these scheduling strategies include Round Robin and First In First Out(FIFO).
What is Batch Processing?
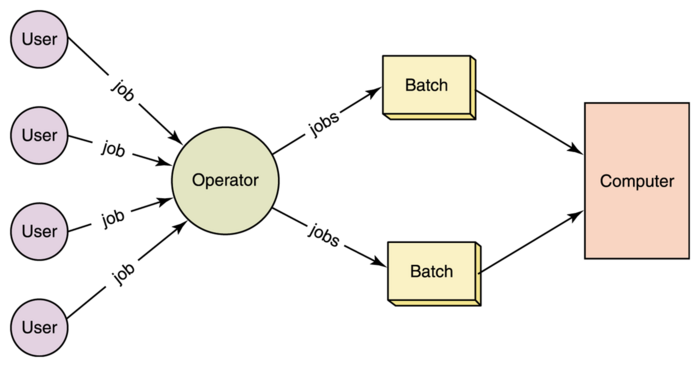
Batch data processing involves gathering substantial volumes of data over a period and then processing the accumulated data(batch) in one go. Rather than handling each data record individually as they are received, the system holds and batches them together for a combined processing run.
This method traces back to the initial stages of computer processing when computing operations were largely manual. In those early days, operators would gather numerous punch cards, each holding specific data or commands, and then feed them collectively into machines for simultaneous processing. This was not only efficient but also necessary, given the technological limitations of the era. As technology has advanced, batch processing has evolved, too, finding its niche in modern applications where processing large, accumulated data sets at once can lead to optimization in terms of computational resources and time.
Benefits
- Efficiency: Processing thousands of data points simultaneously significantly reduces the time the system would have spent handling each data point individually.
- Reduced System Overhead: Batch processing minimizes procedural overheads, which refer to the extra time taken to initiate or conclude a process. By grouping numerous data points into one batch, the system incurs just one overhead, leading to time savings and heightened efficiency.
Use Cases and Applications
- Recommendation systems: Batch processing plays a crucial role in training and updating recommendation models. These models encompass millions of data points, such as user ratings and purchased items. Utilizing real-time or stream processing for such vast data would be time-consuming. Hence, batch processing proves to be a more efficient approach in this context.
- Image Processing: With images containing millions of pixels, batch processing can be used to process all the pixels all at once, saving a great amount of time. This task is typically carried out using GPUs, a specialized version of the standard CPU, optimized for batch computations.
Challenges
- Flexibility of handling data variations: Batch processing systems typically anticipate that all incoming data is uniform, expecting them to undergo identical processing steps. If there are variations in the data, it can potentially lead to computational errors.
- Delayed Processing: Contrary to real-time and stream processing, batch processing accumulates a substantial amount of data before initiating the processing. This approach can be inefficient when an instantaneous response is crucial for the user.
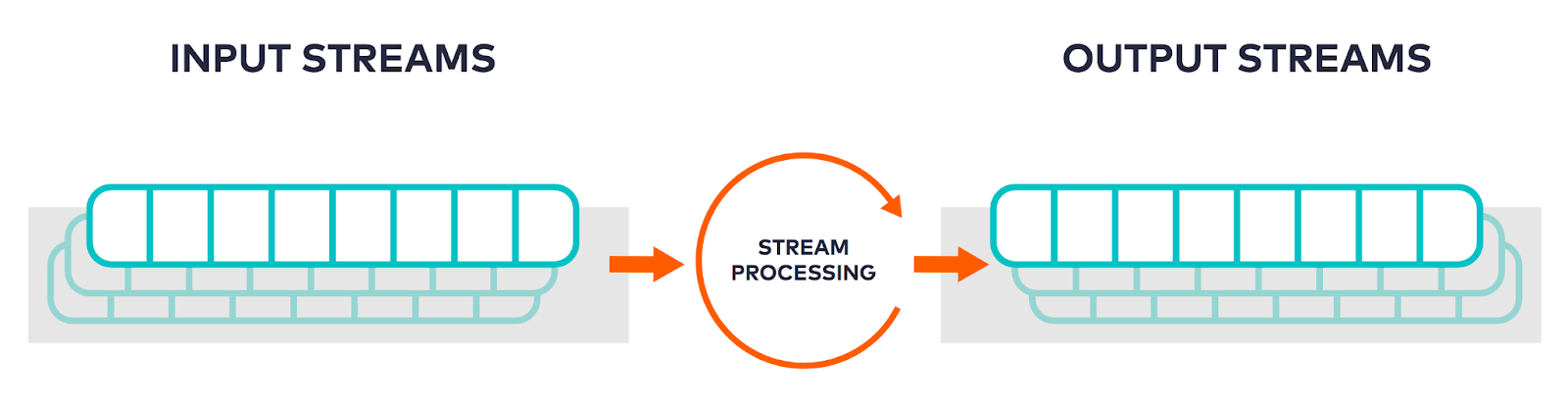
What is Stream Processing?
At a glance, data stream processing might appear akin to real-time processing, but closer inspection reveals distinct differences between the two methodologies. Fundamentally, stream processing is about the continuous and immediate management of data. A notable distinction lies in its capability to handle multiple data streams, possibly originating from varied sources. Moreover, while real-time processing emphasizes predictable and instantaneous responses to individual data inputs, stream processing places a greater emphasis on processing extensive and continuous data flows, regardless of the source.
Benefits
- Scalability: Given that stream processing is inherently designed to handle vast amounts of data, it's unsurprising that it's well-suited for enhanced scalability as well.
- Real-time Insights: Similar to real-time processing, Stream processing allows businesses and organizations to analyze and act upon data in real-time. This immediacy can be crucial for applications such as fraud detection, where rapid response can prevent malicious activities.
Use Cases and Applications
- Online Streaming: Some of the prime examples where Stream processing does shine include Netflix, Amazon, Twitch, and Disney+. To deliver optimal viewing experiences, these services dynamically tailor the streaming quality according to the user's internet bandwidth.
- Building Recommendation Systems: Stream processing plays a vital role in powering real-time recommendation systems. As users interact with content, every action they take generates data. Stream processing captures this data instantly, updating user profiles and preferences on the fly.
Challenges
- Complexity in Handling Late Data: Given the continuous stream of data, handling late data arriving data into the already processed stream can cause some challenges.
- Fault Tolerance: Given the continuous nature of stream processing, any system failure can lead to data loss or processing interruptions.
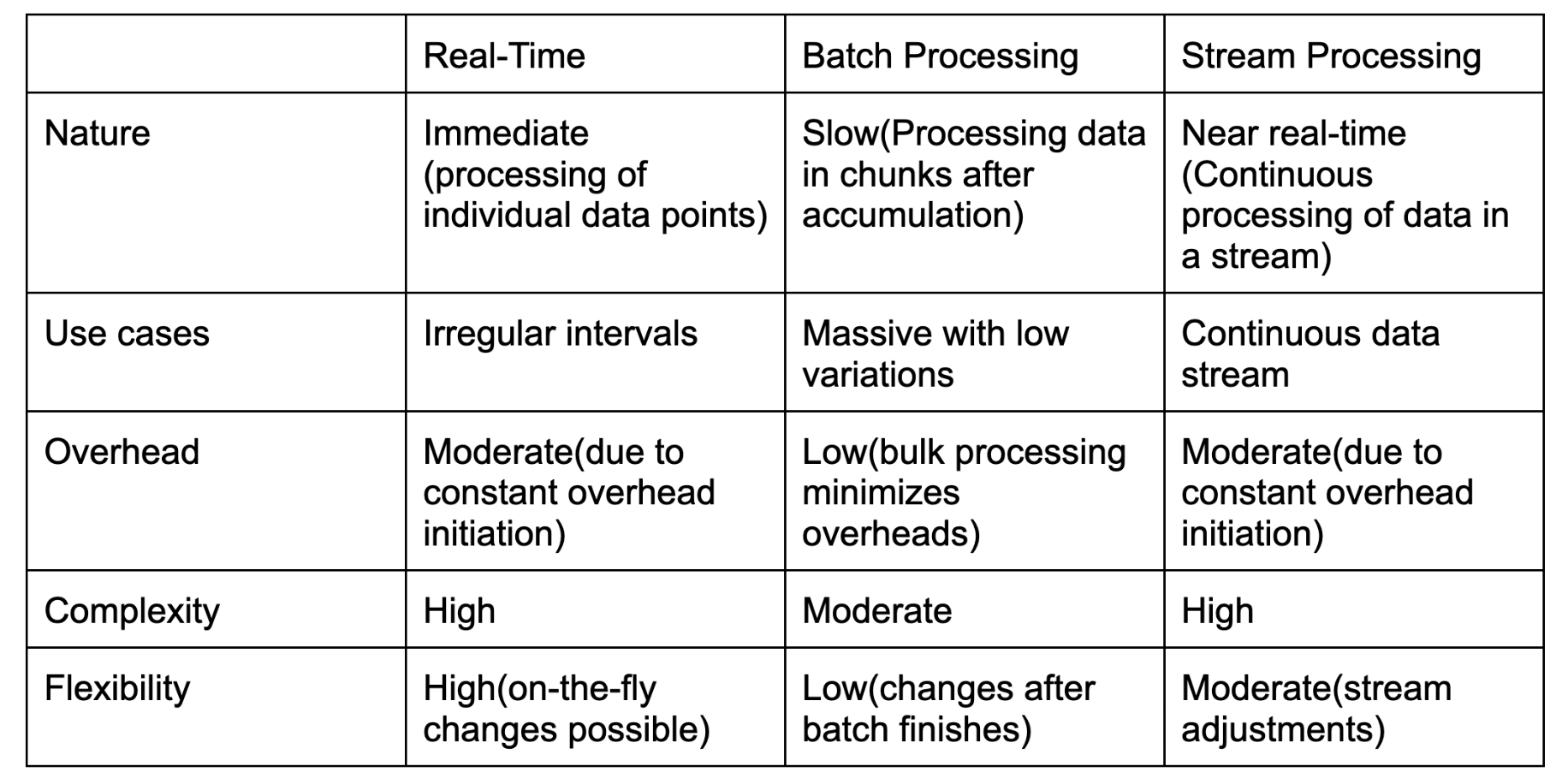
Real-Time Vs. Batch Processing Vs. Stream Processing Comparison Table
Which Processing Methodology is the Best?
The right answer to this question often hinges on the specific task at hand. If a swift and immediate response is required, then real-time processing is the ideal choice. For handling large volumes of tasks that undergo similar processing, batch processing is the way to go. On the other hand, if there's a continuous flow of data points, stream processing is necessary. Nonetheless, we trust that this article has guided you in determining the most suitable processing method for your needs.






.jpg)
