




4.4 Replication System Update
In Harper 4.4, we introduced a new built-in replication system, “Plexus.” This system provides substantial performance, security, and reliability improvements. Plexus eliminates the need to go through a message broker and instead implements direct connections between nodes. This facilitates optimizations down to the TCP level, highly secure mTLS connection, and robust consistency tracking. This highly optimized system for delivery of replicated writes has yielded significant performance gains. Although many factors create variability in test results, we are confident that results show an average 50% increase in replicated write performance over Harper 4.3.
Interpreting the Benchmark Results
The tests specifically focused on measuring throughput for replicated writes and do not reflect write performance for single standalone nodes. In all, 12 different tests were performed across 4, 5, 6, and 8 node clusters, with all writes fully replicated to all nodes. Tests were further divided into two groups, one with random primary keys (Random IDs) and the second with sequential keys (Sequential IDs), to understand variability across use cases.
Given the small sample size and the hundreds of potential unseen performance variables at play when using cloud virtual machines, the 6-node Random IDs result was removed after it demonstrated a 121% increase in performance. With outliers removed, the remaining results showed a mean performance improvement of 51% with a standard deviation of 9%.
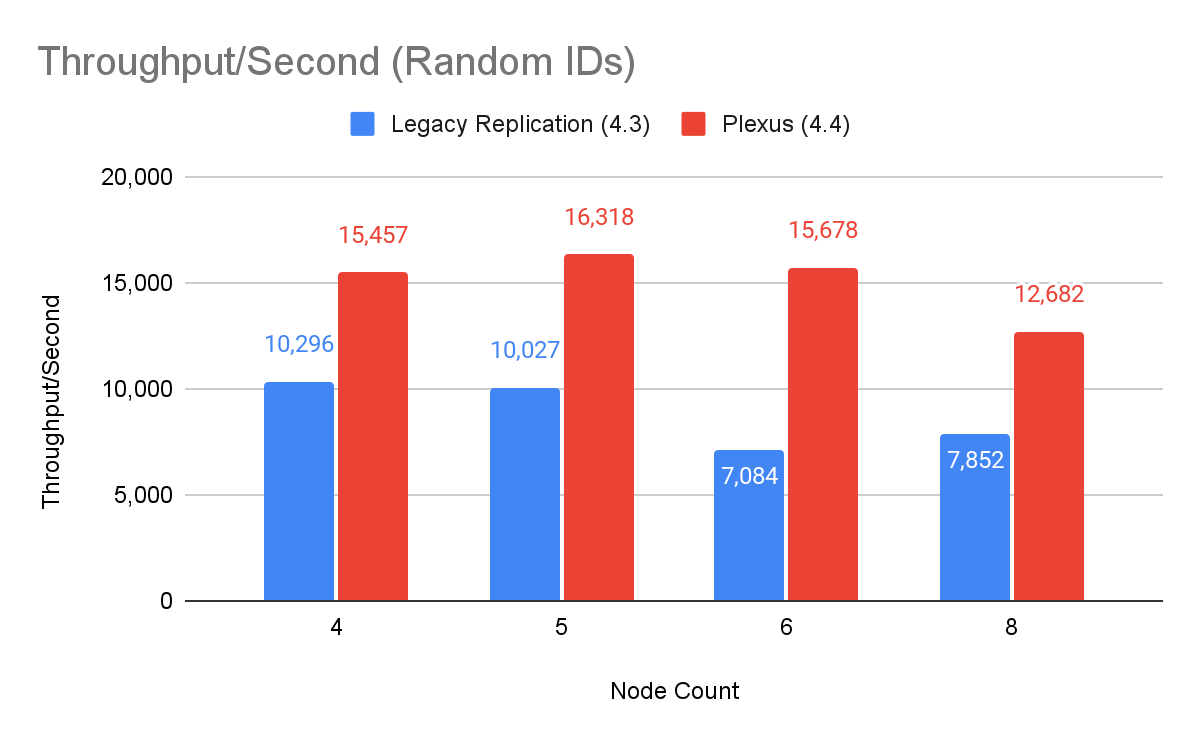
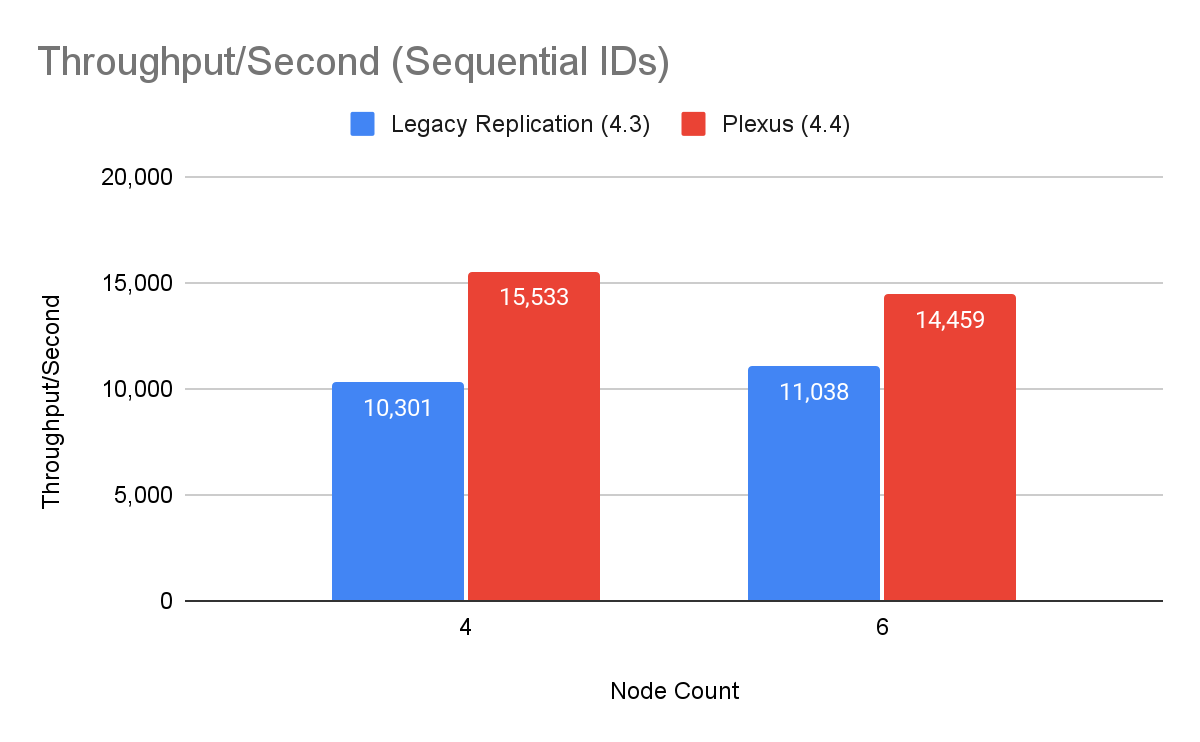
It is worth noting that sharding was not enabled for these tests. With sharding enabled, higher overall write throughput can be expected across the system, as writes are not committed to each independent node.
Test Setup
Benchmarks utilized a multi-node Harper cluster and compared database write performance given the following specifications:
- Record Size: 400 bytes, 8 fields
- High concurrency: 500 virtual users writing
- All writes are new records (inserts) using the POST method of the REST API and are replicated to all other nodes.
- ID Specifications: some text
- Random IDs: Primary keys that are random UUIDs (this is a little slower than sequential IDs, but more reflective of typical usage patterns in practice)
- Sequential IDs: Primary keys that are sequentially generated.
- All tests were performed on 16GB Dedicated CPU Compute Akamai Connected Cloud Instances.
- The tests used a separate instance for each Harper node and another separate instance to execute the load test runner.
- The load tests were performed by k6.





.jpg)
