




Introduction to Caching
Caching is a pivotal technique in computing, serving as a temporary storage mechanism that significantly accelerates data retrieval. By storing copies of files or computational results in strategic locations, caching reduces the necessity to repeatedly access the original data source by retrieving the data from closer storage sources, which reduces network usage overall.
Whether it’s a database or a web server, caching optimizes overall system performance and user experience.
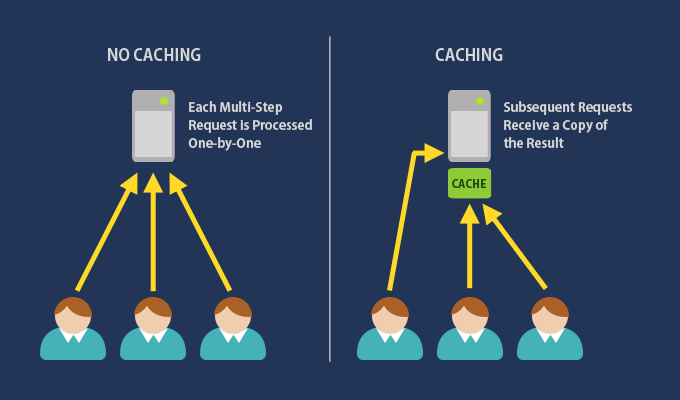
The utility of caching is evident in scenarios where swift data access is imperative, like in high-traffic web services, e-commerce platforms, and content delivery networks.
This article delves into two of the main caching strategies: active and passive caching. Each of these mechanisms follows a unique approach to data storage and retrieval and explores their respective benefits, use cases, and implementation considerations. The objective is to provide a clear understanding of these strategies, enabling informed decision-making for developers, system architects, and IT professionals in aligning the caching mechanism with the specific needs and constraints of their systems.
Passive Caching
Passive caching is a caching strategy that only saves data to the cache server after a user has asked for it. This means the cache only holds information that users have actually needed, making sure it uses storage wisely by not keeping unnecessary data. In short, it waits for a user’s action and then responds by storing the needed data, keeping things simple and user-focused.
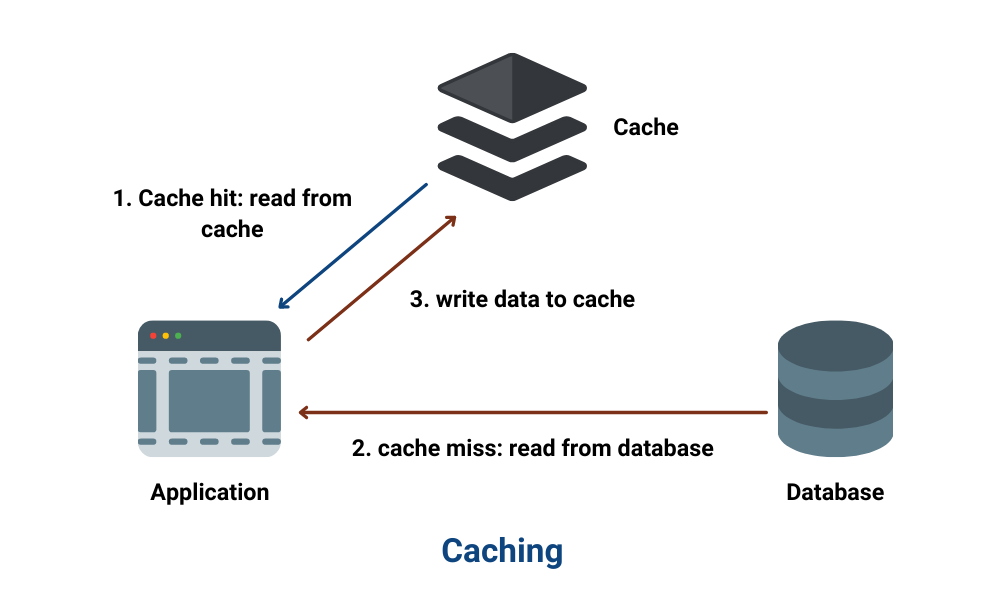
When a user requests data, the system checks whether that data stored is in the cache. If the data is not in the cache (a cache miss), the system will retrieve the data from the source, serve it to the user, and store it in the cache for future requests. If the data is in the cache (a cache hit), it will be served directly from the cache.
Such a caching strategy is often the standard caching mechanism in web browsers or proxy servers, where previously requested web pages or files are stored in the cache.
Benefits of Passive Caching
- Simpler Mechanism: Usually simpler to implement and manage due to its reactive nature.
- Efficient: Typically less resource-intensive as it only stores data that has been requested.
- Reactive: It reacts to user requests and only then stores data in the cache.
Drawbacks of Passive Caching
- Delayed First Response: The first request for the data will experience normal latency, as the data is not yet in the cache, leading to a higher response time.
Pseudocode Example for Passive Caching
Active Caching
Active caching operates as an enhanced counterpart to the more conventional passive caching mechanism, elevating its functionality by encompassing a more complex caching approach.
Such a caching system actively retrieves and stores data in the cache before the user requests it. The system predicts which data the user or system is likely to request next and proactively loads that data into the cache, thus reducing the wait time for the user.
Such a system often involves algorithms or mechanisms to predict which data will be needed next. This is more commonly used for prefetching cached data in web browsers or content delivery networks based on user behavior and navigation patterns. Significantly improving application performance.
Having said that, there are a couple of different active caching approaches. Each approach has its pros and cons.
Benefits of Active Caching
- Reduced Latency: Can significantly reduce the latency for serving requests as cached data is preloaded.
- Optimized for Predictability: Can significantly benefit systems where user behavior and data access patterns are predictable,
Drawbacks of Active Caching
- Resource Intensive: Can be more resource-intensive due to the constant need to predict and load data that the above algorithms require.
- Complex Implementation: Implementation can be a bit more complex due to the need for accurate predictive algorithms and mechanisms to determine what data to cache.
Types of Active Caching
- Eager Loading: Eager loading is a strategy where associated/relevant data is loaded simultaneously with the parent data, reducing the number of subsequent requests needed to fetch related information.
Pseudocode Example for Eager Loading Active Caching
- Origin Offloading: In contrast to the previously mentioned active caching method, Origin Offloading is specifically tailored for database-oriented caching. As the name implies, Origin Offloading refers to the process of reducing the load on the primary(origin) server. This is achieved by serving user requests from a caching layer instead of the main server itself. (It's like CDN, but for the entire or selected portion of the origin database and with the ability to query).
In the case of Origin Offloading, instead of just passively waiting for a database read to then store it in the cache, we have an active layer that subscribes to changes in the original database. Whenever there's an update or a change in the origin record, our caching layer is instantly made aware and updated accordingly.
In this essence, the cache isn't just a passive entity; it's an active participant, constantly synchronizing with the origin, ensuring data consistency and availability across regions.
Contrary to traditional active caching techniques, Origin Offloading emerges as the ideal solution for major e-commerce giants such as eBay or Target, as well as gaming behemoths like Ubisoft or Nintendo. These enterprises stand to gain significantly from caching that transcends the boundaries set by CDNs, ensuring every user experience is seamlessly accelerated.
Pseudocode Example for Origin Offloading Active Caching
This type of caching in databases can be ideal for mega e-commerce enterprises like eBay or Target and gaming brands like Ubisoft or Nintendo for several reasons, as it can significantly enhance the overall user experience and improve system performance. This is due to a multitude of reasons such as:
- Personalization: E-commerce platforms rely on user data to provide personalized product recommendations, while gaming companies use player data for matchmaking and in-game experiences. Active caching allows them to store and update personalized data efficiently, delivering tailored experiences to users in real time.
- Content Adaptation: Gaming brands may use caching to adapt content based on user location or device capabilities. For example, caching game assets optimized for a specific region or device can improve download and gameplay performance.
- High Availability: Active caching solutions can provide high availability and fault tolerance by replicating cached data across multiple servers or data centers. This ensures that even if one cache server fails, there is minimal impact on the user experience.
- Real-time Analytics: Ecommerce enterprises can benefit from caching to support real-time analytics and reporting, enabling them to make data-driven decisions quickly. This is crucial for inventory management, pricing optimization, and marketing campaigns.
- Improved CDN Integration: While CDNs excel at caching static assets like images and videos, active caching complements CDNs by caching dynamic content and database queries. This comprehensive caching strategy ensures that every aspect of the user experience is accelerated, not just static assets.
Summary
To wrap up, both active and passive caching strategies play critical roles in optimizing data access and system performance, with their suitability being contingent on the specific demands and resources of a given application or service.
Active caching is especially beneficial in environments where minimizing latency is crucial, such as in real-time web applications and high-traffic services, despite its inherently higher resource consumption and implementation complexity.
On the other hand, passive caching is a go-to strategy when simplicity and resource efficiency are prioritized, particularly suitable for systems with unpredictable or spontaneous data requests.
Choosing the right caching strategy entails a thorough evaluation of user behavior, system architecture, performance goals, and available resources. Often, a balanced or hybrid approach, combining elements of both strategies, yields optimal results, ensuring a seamless user experience and efficient resource utilization in varied and dynamic computing environments.
When well implemented, the right caching strategy can substantially enhance application responsiveness and scalability, fostering improved user satisfaction and system reliability. To learn more about Harper’s caching capabilities, visit the website here.






.jpg)
